安卓手机本地AI模型部署完全指南
- 2026-07-02 21:46:11
让您的安卓手机成为口袋里的超级大脑
前言:为什么要在手机上部署本地AI?
在这个云计算主导的时代,我们似乎已经习惯了将所有计算任务交给远程服务器处理。然而,当您深入了解本地AI部署的魅力后,可能会重新审视这种依赖关系。本地AI不仅仅是一种技术选择,更代表着一种对数字主权和隐私保护的追求。
本地AI与云端AI的全面对比
在做出部署决策之前,我们需要深入理解本地部署与云端服务之间的本质差异。这种差异不仅体现在技术层面,更深刻地影响着我们的使用体验和价值观念。
费用结构方面,云端API服务通常采用按调用次数或token数量计费的模式。以当前主流的大语言模型API为例,每百万token的调用费用可能从几美分到几美元不等。对于重度用户而言,每月的API支出可能轻松突破几十甚至上百美元。相比之下,本地部署的AI模型虽然需要前期投入时间进行配置和可能的硬件升级(如果您需要额外的散热设备),但一旦部署完成,后续使用完全免费。这种一次投入、永久受益的模式对于长期使用者来说极具吸引力。
隐私安全方面,这是本地AI最核心的优势之一。当您使用云端API时,所有的对话数据都会被上传到远程服务器进行处理。这些数据可能被用于模型训练、服务改进,甚至在某些情况下可能面临数据泄露的风险。而本地部署的AI模型完全在您的设备上运行,数据永远不会离开您的手机。这意味着您可以放心地处理敏感信息,如个人财务数据、医疗记录、商业机密等,而无需担心隐私泄露。
网络依赖方面,云端AI服务对网络质量有严格要求。在网络信号不佳的环境下,如地铁、飞机、偏远地区或地下室,云端服务的响应速度会显著下降甚至完全无法使用。而本地AI完全离线运行,不受任何网络条件限制。无论您身处何地,只要手机有电,AI助手就能随时待命。这种可靠性对于经常出差或在特殊环境下工作的用户来说尤为重要。
定制化能力方面,云端AI对普通用户来说基本是一个黑盒系统。您无法修改模型的内部结构,无法针对特定领域进行优化,也无法调整生成策略来满足个性化需求。而本地部署的AI模型则完全开放,您可以微调模型以适应特定领域(如法律、医学、编程),调整温度参数控制创造性,或实施特定的过滤规则。这种灵活性使得本地AI能够更好地服务于个性化需求。
使用限制方面,云端API通常设有速率限制和调用配额。免费层用户可能面临每分钟或每天的调用次数限制,即使付费用户也可能遇到高峰期的限流问题。本地AI则没有这些限制,您可以无限次地与模型交互,进行长篇文档分析,或进行批量处理任务。这种自由度和灵活性是云端服务难以提供的。
本地AI的典型适用场景
理解本地AI的价值定位后,我们需要明确它在哪些场景下能够发挥最大作用。以下是一些最具代表性的应用场景:
无网络环境下的紧急需求是本地AI最直接的应用场景。当您乘坐地铁穿越隧道、乘坐国际航班、或者在网络覆盖较差的户外地区时,云端AI服务可能完全不可用。此时,一个运行良好的本地AI助手可以帮您完成翻译、写作、计算等各种任务,确保工作不受网络条件影响。
敏感信息的处理是本地AI的另一个核心应用领域。如果您从事法律、医疗、金融等行业,经常需要处理高度敏感的客户信息,使用云端API可能违反保密规定或行业法规。本地部署的AI可以确保这些信息始终在受控环境中处理,既满足合规要求又不牺牲工作效率。
预算受限的个人用户和学生群体会发现本地AI是一个极具吸引力的选择。对于刚开始学习AI技术或需要频繁使用AI辅助功能但预算有限的用户来说,本地部署避免了持续的API费用支出。虽然前期需要投入时间进行配置,但这种一次性投入可以带来长期的免费使用体验。
需要定制化功能的开发者可以利用本地AI的开放性进行各种创新尝试。您可以将本地AI集成到自己的应用程序中,针对特定领域进行模型微调,或者开发独特的AI功能。这种实验和创新的自由度是封闭的云端服务所无法提供的。

第一章:准备工作——选择合适的模型
在开始部署之前,选择合适的模型是整个项目成功的关键。模型的选择需要综合考虑手机的硬件配置、预期的使用场景以及对响应质量的要求。过大的模型可能导致手机崩溃或响应缓慢,而过小的模型可能无法满足您的实际需求。
1.1 理解手机硬件限制
安卓手机的硬件配置差异很大,从入门级的4GB RAM设备到旗舰级的16GB RAM手机都有。要在手机上成功运行本地AI,首先需要准确评估自己设备的性能边界。
**运行内存(RAM)**是决定能够运行多大模型的最关键因素。现代大语言模型在推理时需要将模型参数加载到内存中,同时还需要额外的内存空间来存储KV缓存和中间计算结果。以一个7B参数(70亿参数)的模型为例,在FP32精度下需要约28GB的内存空间。即使采用4位量化,7B模型仍需要约4GB的内存来存储参数。考虑到操作系统和其他应用程序的内存需求,运行7B量化模型至少需要6-8GB的可用RAM。这意味着配备8GB RAM的手机在理想情况下可以运行7B量化模型,但可能会比较勉强;而配备12GB或更多RAM的手机则可以更加从容地运行这类模型。
处理器性能决定了模型的推理速度。虽然大语言模型的推理主要在CPU上完成(Llama.cpp针对ARM架构进行了优化),但更快的CPU能够显著提升token生成速度。当前旗舰级安卓芯片(如骁龙8 Gen系列和天玑9300系列)配备的Cortex-X核心能够提供较强的单线程性能,这对于LLM推理非常有帮助。不过需要注意的是,由于手机散热限制,处理器在持续高负载下可能会降频,导致性能随时间下降。
存储空间虽然不是运行时的瓶颈,但会影响模型的加载速度。UFS 4.0等高速存储技术可以加快模型文件的读取速度,而较慢的存储介质则可能导致较长的模型加载时间和更频繁的卡顿。此外,部分手机支持将存储卡格式化为内部存储,这为需要尝试多个模型的用户提供了更大的灵活性。
1.2 按配置选择最佳模型
根据不同的手机配置,我们推荐以下模型选择策略:
**入门级手机(4GB RAM)**应该选择参数量在1B到2B之间的小型模型。这类模型虽然能力有限,但可以在较低的配置下稳定运行。推荐尝试Phi-2(2.7B参数,微软开发,专为推理优化)或TinyLlama(1.1B参数,基于Llama架构的轻量版本)。这些模型的量化版本(Q4_K_M或更激进的量化)通常在700MB到1GB之间,对内存的压力较小。响应速度方面,这类模型通常可以达到每秒10-20个token的生成速度,足以满足基本的对话需求。
**中端手机(6-8GB RAM)**具备了运行更大模型的能力,推荐选择1.5B到4B参数范围内的模型。Qwen2.5-1.5B(阿里开发,中文能力强)或Llama-2-7B的4位量化版本是很好的选择。这类模型在保持较快响应速度的同时,提供了更强的语言理解和生成能力。Qwen2.5-1.5B特别值得推荐,因为它在中文理解方面表现优异,且模型体积适中(约1GB),非常适合在手机上运行。
**高端手机(12GB+ RAM)**可以尝试3B到7B参数范围内的模型。Qwen2.5-3B、Llama-2-7B(Q5_K_M量化)或Yi-1.5-6B都是不错的选择。更强的硬件配置意味着您可以在模型大小和响应速度之间取得更好的平衡。这类模型能够处理更复杂的任务,提供更高质量的输出,虽然生成速度可能略慢于小型模型,但输出质量的优势足以弥补这一差距。
1.3 模型量化技术详解
理解模型量化是选择合适模型的关键。量化是一种通过降低模型权重精度来减少模型体积和内存占用的技术。
为什么需要量化?原始的预训练模型通常使用FP32(32位浮点数)精度存储每个参数,这意味着每个参数占用4个字节。对于一个7B参数的模型,仅存储权重就需要28GB的空间,显然超出了任何手机的承载能力。通过量化技术,我们可以将权重从FP32转换为更低精度的表示,如INT8(8位整数,每个参数1字节)或INT4(4位整数,每个参数0.5字节)。使用INT4量化后,7B模型只需要约4GB的存储空间,这使得在手机上运行成为可能。
GGUF格式是目前在手机上运行本地AI的首选格式。GGUF(前身为GGML)是一种专门为本地推理优化的模型格式,具有以下优势:良好的压缩率、支持多种量化级别、跨平台兼容性、内存映射支持。Llama.cpp原生支持GGUF格式,这意味着您可以直接使用这个格式的模型进行推理,无需额外的转换步骤。
量化级别选择需要权衡模型质量和资源消耗。常见的量化级别包括:
Q4_0:最激进的4位量化,体积最小但质量损失较大 Q4_K_M:平衡的4位量化,在体积和质量之间取得较好平衡,推荐作为默认选择 Q5_K_M:5位量化,质量接近完整精度但体积增加约25% Q8_0:8位量化,质量接近原始模型但体积较大
对于大多数手机用户,Q4_K_M是最佳选择,它在保持可接受质量的同时将体积控制在合理范围内。只有当您拥有充足RAM且对生成质量有较高要求时,才需要考虑Q5_K_M或更高精度的量化版本。

第二章:基础环境部署——Termux配置详解
Termux是一个在安卓手机上运行的终端模拟器和Linux环境应用。它提供了一个完整的Linux命令行界面,使我们能够在手机上执行各种开发任务,包括编译和运行本地AI模型。
2.1 Termux安装与初始化
正确的Termux安装是整个部署过程的第一步,也是最关键的一步。安装来源的选择会直接影响后续的使用体验和稳定性。
安装源选择是新手容易忽视但非常重要的问题。我们强烈建议从F-Droid(https://f-droid.org)下载Termux,而不是Google Play Store。原因是Google Play上的Termux版本已经停止更新多年,存在兼容性问题且无法获取最新功能。F-Droid版本保持活跃更新,修复了众多bug并添加了新特性。如果您已经在使用Google Play版本的Termux,建议卸载后重新从F-Droid安装。
首次启动配置完成后,您会看到Termux的命令行界面。第一步是更新软件包列表并升级现有软件包,这可以确保您拥有最新的安全修复和功能改进。
1 2 3 4 5
# 更新软件包列表pkg update# 升级已安装的软件包pkg upgrade -y
这个过程可能需要几分钟时间,取决于您的网络速度和已有软件包的数量。完成后,Termux环境就已经准备就绪,可以开始安装所需的工具了。
2.2 必需软件包安装
为了编译和运行Llama.cpp以及相关工具,我们需要安装一系列开发工具和依赖库。
编译工具链是后续所有工作的基础。clang编译器、cmake构建系统、make工具以及ninja构建系统都是编译Llama.cpp所必需的。这些工具提供了将源代码转换为可执行程序的能力。
1 2
# 安装编译工具链pkg install -y clang cmake make ninja binutils
Git版本控制用于从GitHub等代码仓库克隆项目。Llama.cpp托管在GitHub上,我们需要使用git来获取源代码。
1 2
# 安装Gitpkg install -y git
Python环境虽然Llama.cpp本身是C++编写,不需要Python,但许多辅助工具和模型转换脚本依赖Python。如果您计划使用text-generation-webui等更高级的界面,Python环境更是必不可少的。
1 2
# 安装Python及其开发文件pkg install -y python python-pip
下载工具用于从网络获取模型文件。虽然可以从电脑传输模型文件,但直接在手机上下载更加便捷。
1 2
# 安装wget和curlpkg install -y wget curl
科学计算库可能对某些模型推理加速有帮助。OpenBLAS提供了优化的线性代数运算实现。
1 2
# 安装BLAS库pkg install -y openblas libopenblas liblapack
2.3 存储权限与目录设置
Termux默认只能访问自己的私有目录。为了存储模型文件和处理较大的数据,您需要授予Termux访问手机存储的权限。
授予存储权限是一个简单的操作,但在后续步骤中至关重要。
1 2
# 授予存储访问权限termux-setup-storage
执行此命令后,Termux会请求存储权限。点击"允许"后,您就可以在Termux中访问手机的共享存储了。通常这个权限会被授予到/storage/emulated/0目录,您还会在主目录创建一个名为storage的符号链接,指向这个位置。
创建工作目录结构有助于保持文件的组织性和可管理性。我们建议创建一个清晰的文件层级。
1 2 3 4 5 6 7
# 创建项目目录mkdir -p ~/local_ai/models # 存放模型文件mkdir -p ~/local_ai/projects # 存放项目代码mkdir -p ~/local_ai/data # 存放数据文件# 进入工作目录cd ~/local_ai
2.4 虚拟内存配置
安卓系统的内存管理策略可能不够激进,当物理内存不足时,系统可能不会及时释放内存或使用交换空间。为了提高模型运行的稳定性,配置交换文件(虚拟内存)是一个有效的策略。
创建交换文件是增加可用内存的最简单方法。交换文件使用硬盘空间来模拟内存,虽然速度比真实内存慢,但可以有效防止因内存不足导致的程序崩溃。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# 检查当前内存和交换空间使用情况free -h# 创建2GB交换文件(根据需要可以增加到4GB)ddif=/dev/zero of=$HOME/swapfile bs=1M count=2048# 设置正确的权限(只有root用户可以读写)chmod 600 $HOME/swapfile# 初始化交换文件mkswap $HOME/swapfile# 启用交换文件swapon $HOME/swapfile
使交换文件永久生效需要在系统启动时自动挂载。我们可以通过将挂载命令添加到启动脚本中来实现。
1 2 3 4 5
# 将挂载命令添加到.bashrc(每次启动Termux时执行)echo"swapon $HOME/swapfile" >> ~/.bashrc# 或者添加到.profile(更通用的登录脚本)echo"swapon $HOME/swapfile" >> ~/.profile
需要注意的是,交换文件会占用手机存储空间,如果您的手机存储空间紧张,可以使用较小的交换文件(如1GB),或者在运行时手动管理交换空间。
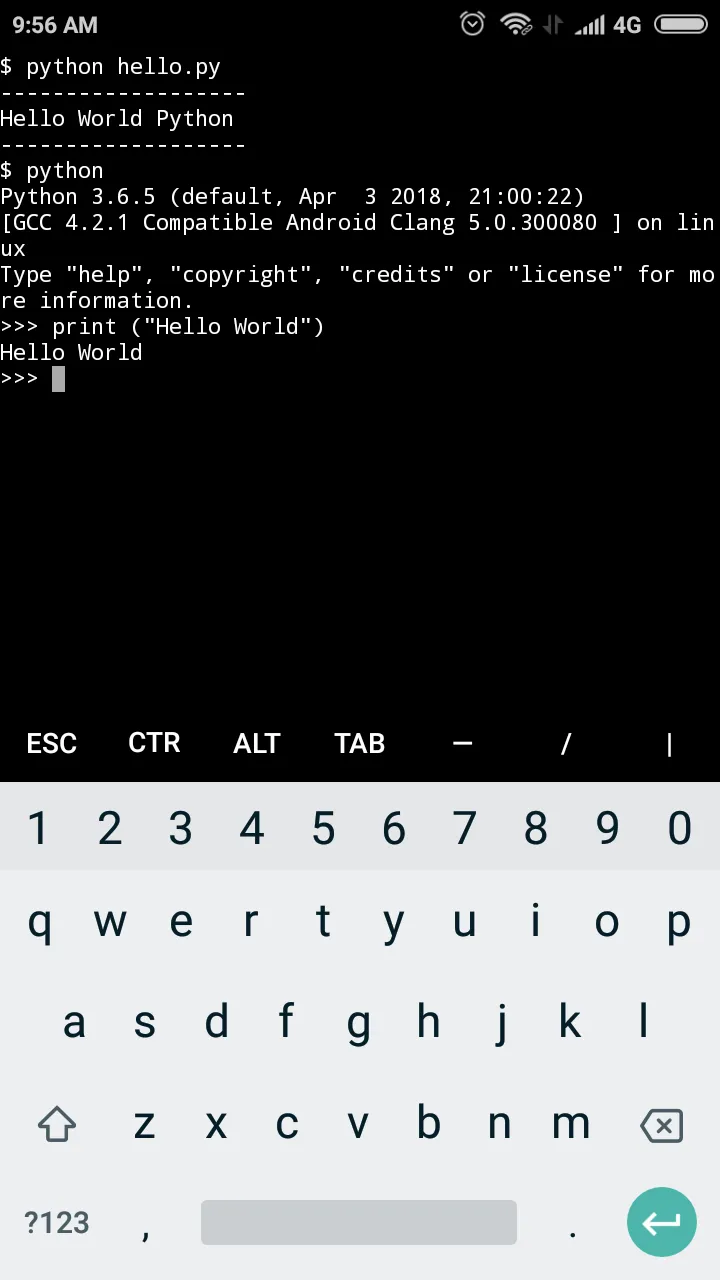
第三章:部署Llama.cpp——手机AI核心引擎
Llama.cpp是目前最流行的本地大语言模型推理引擎之一。它由Georgi Gerganov开发,采用纯C++编写,针对各种硬件平台进行了深度优化。在手机上运行本地AI,Llama.cpp几乎是必然的选择。
3.1 为什么选择Llama.cpp
在众多的大语言模型推理框架中,Llama.cpp凭借其独特的优势成为手机端部署的首选方案。
极高的资源效率是Llama.cpp最显著的特点。与PyTorch等通用深度学习框架相比,Llama.cpp针对推理场景进行了专门优化,去除了大量训练相关的代码和依赖。它的二进制文件体积小,启动速度快,内存占用低。这对于资源受限的手机环境来说至关重要。
纯C++实现意味着Llama.cpp不依赖Python运行时环境,减少了额外的开销。同时,C++的跨平台特性使得Llama.cpp可以在各种操作系统和处理器架构上运行,从x86服务器到ARM手机都能获得良好的支持。
GGUF格式原生支持使Llama.cpp与当前最流行的本地模型格式无缝衔接。您可以直接使用Hugging Face上提供的GGUF格式模型,无需任何转换步骤。
活跃的社区支持确保了Llama.cpp持续改进和功能更新。开发者社区非常活跃,bug修复及时,新功能(如更高效的量化方法、更好的采样策略)持续加入。遇到问题时,您可以在GitHub Discussions或Reddit上获得帮助。
3.2 从源码编译Llama.cpp
虽然Llama.cpp提供了预编译的二进制文件,但从源码编译可以获得针对您手机处理器的优化版本,带来更好的性能。我们将使用clang编译器进行编译。
克隆代码仓库是第一步。从GitHub获取最新的Llama.cpp源代码。
1 2 3 4 5 6
# 回到主目录cd ~# 克隆Llama.cpp仓库(使用镜像源加速)git clone https://github.com/ggerganov/llama.cppcd llama.cpp
执行编译是整个过程中最耗时的步骤。编译过程会将C++源代码转换为可执行文件,针对ARM架构进行优化。
1 2 3 4 5 6
# 清理可能的旧编译文件(如果是重新编译)make clean# 使用clang进行编译# -j4表示使用4个并行任务加速编译make -j4
编译过程中您会看到大量的编译输出,包括源文件的编译和链接过程。如果编译成功完成,您会在项目根目录下看到main和server等可执行文件。
验证编译结果确保一切正常:
1 2 3 4 5
# 检查生成的可执行文件ls -lh ./main ./server# 查看main程序的帮助信息./main --help
如果./main --help输出了详细的参数说明,说明编译成功,您现在拥有了一个可以在手机上运行的AI推理引擎。
故障排除:如果编译过程中出现错误,常见原因包括:
内存不足:尝试减少并行任务数,将 -j4改为-j2甚至-j1编译器问题:确保已正确安装clang 依赖缺失:检查是否安装了所有必需的开发包
3.3 安装模型转换工具(可选)
如果您需要将其他格式的模型转换为GGUF格式,或者进行模型量化,需要安装额外的工具。Llama.cpp提供了完整的模型转换和量化工具链。
1 2 3 4 5
# 安装模型转换所需的Python依赖pip install -r requirements.txt# 安装convert.py脚本所需的 huggingface_hub 库pip install huggingface-hub
这些工具在后续章节的模型转换和自定义模型处理中会用到。现在您可以暂时跳过此步骤,等到需要时再安装。
第四章:运行第一个本地AI模型
万事俱备,现在可以开始运行您的第一个本地AI模型了。我们将从下载模型开始,逐步完成一次完整的对话体验。
4.1 下载并准备模型
模型文件通常较大(从几百MB到几GB不等),下载过程可能需要一些时间。我们使用Qwen2.5-1.5B作为入门模型,它在中文理解和生成方面表现出色,同时体积适中。
创建模型目录并下载模型文件:
1 2 3 4 5 6 7 8 9 10 11 12
# 创建模型目录mkdir -p ~/models && cd ~/models# 下载Qwen2.5-1.5B(Q4_K_M量化版本,约1GB)# 使用清华镜像源加速下载wget https://mirrors.tuna.tsinghua.edu.cn/huggingface-models/Qwen/Qwen2.5-1.5B-Instruct-GGUF/qwen2.5-1.5b-instruct-q4_k_m.gguf# 如果镜像源没有该模型,使用官方HuggingFace# wget https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct-GGUF/resolve/main/qwen2.5-1.5b-instruct-q4_k_m.gguf# 验证下载的文件ls -lh *.gguf
下载完成后,您应该看到一个约1GB大小的.gguf文件。这就是可以加载到Llama.cpp中进行推理的模型文件。
4.2 执行第一次推理
现在让我们尝试运行模型。第一次运行会加载模型文件,这可能需要一些时间(取决于模型的加载速度和手机的I/O性能)。
1 2 3 4 5 6 7 8 9 10 11 12 13
# 进入Llama.cpp目录cd ~/llama.cpp# 执行第一次对话./main -m ~/models/qwen2.5-1.5b-instruct-q4_k_m.gguf \-n 256 \-t 4 \--color \-c 2048 \-b 512 \--temp 0.7 \--repeat_penalty 1.1 \-p "你好,请介绍一下你自己"
让我们解释这些参数的含义:
-m:指定模型文件路径-n:最大生成的token数量(响应长度限制)-t:使用的线程数(建议设置为CPU核心数)--color:启用彩色输出,在某些终端中更易阅读-c:上下文长度(影响模型能记住多少对话历史)-b:批处理大小,手机上保持较小值即可--temp:温度参数,控制输出的随机性(较低的值更确定性)--repeat_penalty:重复惩罚,减少模型重复生成相同内容-p:输入提示词
如果一切正常,您会看到模型开始加载,然后逐字生成响应。这就是您的第一个本地AI对话!
4.3 创建便捷的聊天脚本
每次输入这么长的命令很繁琐。我们创建一个便捷的脚本来简化日常使用。
1 2
# 创建聊天脚本nano ~/local_ai/chat.sh
将以下内容复制到脚本中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
#!/data/data/com.termux/files/usr/bin/bash# 颜色定义GREEN='\033[0;32m'BLUE='\033[0;34m'YELLOW='\033[1;33m'NC='\033[0m'# No Colorecho -e "${GREEN}======================================"echo -e " 🤖 本地AI聊天助手 v1.0"echo -e "======================================${NC}"MODEL_PATH="$HOME/models/qwen2.5-1.5b-instruct-q4_k_m.gguf"LLAMA_DIR="$HOME/llama.cpp"cd$LLAMA_DIR# 检查模型是否存在if [ ! -f "$MODEL_PATH" ]; thenecho -e "${YELLOW}⚠️ 模型不存在,请先下载模型!${NC}"echo""echo"下载命令:"echo"mkdir -p ~/models && cd ~/models"echo"wget https://mirrors.tuna.tsinghua.edu.cn/huggingface-models/Qwen/Qwen2.5-1.5B-Instruct-GGUF/qwen2.5-1.5b-instruct-q4_k_m.gguf"exit 1fiecho -e "${GREEN}✅ 模型已就绪: $(basename $MODEL_PATH)${NC}"echo -e "${YELLOW}💡 输入 'quit' 或 'exit' 退出聊天${NC}"echo -e "${BLUE}--------------------------------------${NC}"echo""# 主循环whiletrue; doecho -ne "${GREEN}👤 你: ${NC}"read -r user_inputif["$user_input"="quit"]||["$user_input"="exit"]; thenecho -e "${GREEN}👋 再见!期待下次聊天!${NC}"breakfiif [ -z "$user_input" ]; thencontinuefiecho -e "${BLUE}🤖 AI: ${NC}"# 执行推理./main -m "$MODEL_PATH" \-t 4 \-c 1024 \-b 128 \-n 256 \--temp 0.7 \--color \-p "用户说:$user_input\n助手回答:"echo""done
1 2 3 4 5
# 给脚本添加执行权限chmod +x ~/local_ai/chat.sh# 运行聊天脚本~/local_ai/chat.sh
现在您可以享受更便捷的聊天体验了。这个脚本提供了清晰的界面提示,模型检查功能,以及方便的退出命令。
4.4 关键参数详解
理解Llama.cpp的参数对于优化模型表现至关重要。以下是手机上最常用的参数及其推荐值。
**线程数(-t)**直接影响推理速度,但不是越多越好。建议设置为物理CPU核心数(可在手机设置中查看CPU信息),通常在4到8之间。过高的线程数会增加内存压力并可能导致性能下降。
**上下文长度(-c)**决定了模型能处理多长的输入。过长的上下文会显著增加内存占用,因为模型需要存储大量的KV缓存。对于手机上的轻量使用,512到1024是合理的范围。如果您的手机RAM充足且需要处理长文档,可以增加到2048。
**生成长度(-n)**限制单次回复的最大token数。较长的回复需要更多的生成时间和内存。256到512对于大多数对话场景已经足够。
**温度参数(--temp)**控制输出的随机性。较低的值(0.3-0.5)使输出更确定性,适合需要准确答案的场景;较高的值(0.7-0.9)增加创造性和多样性,适合创意写作。
**重复惩罚(--repeat_penalty)**减少模型重复生成相同短语的情况。值为1.0表示不惩罚,1.1到1.2是常用的范围。过高的值可能导致生成不自然的内容。
手机专用优化参数:
1 2 3 4 5 6
./main -m ~/models/你的模型.gguf \-t 4 \ # 线程数=CPU核心数-c 1024 \ # 小上下文节省内存-b 128 \ # 小批次减少峰值内存--mlock \ # 锁定模型在内存,减少swap--n-predict 256 # 限制最大生成长度
第五章:Web界面——像ChatGPT一样使用
虽然命令行界面功能强大,但可能不够直观。本章将介绍如何在手机上搭建Web界面,提供类似ChatGPT的使用体验。
5.1 使用Llama.cpp内置服务器
Llama.cpp自带了一个轻量级的Web服务器,可以直接在手机浏览器中提供对话界面。
1 2 3 4 5 6 7 8 9
# 启动Web服务器cd ~/llama.cpp./server -m ~/models/qwen2.5-1.5b-instruct-q4_k_m.gguf \-t 4 \-c 1024 \--port 8080 \--host 0.0.0.0 \--ctx-size 1024
参数说明:
--host 0.0.0.0:允许从任何地址访问,包括局域网其他设备--port 8080:指定服务器端口--ctx-size:上下文窗口大小
服务器启动后,打开手机浏览器访问http://localhost:8080,您将看到一个简洁的对话界面。您可以像使用ChatGPT一样与模型对话,支持多轮对话和上下文理解。
5.2 局域网访问配置
通过配置局域网访问,您可以使用电脑或其他设备访问手机上运行的AI服务。
获取手机IP地址:
1 2 3 4 5
# 方法1:使用Termux命令ifconfig | grep "inet addr"# 方法2:使用ip命令ip addr show | grep "inet "
通常您的手机会显示一个类似192.168.x.x的IP地址,这就是局域网IP地址。
启动局域网服务(如果尚未配置):
1 2 3 4 5
./server -m ~/models/qwen2.5-1.5b-instruct-q4_k_m.gguf \-t 4 \-c 1024 \--port 8080 \--host 0.0.0.0
现在,您可以在同一局域网内的电脑上打开浏览器,访问http://<手机IP>:8080,即可使用电脑的浏览器与手机上的AI进行对话。这种方式特别适合需要大屏幕或物理键盘的场景。
5.3 安装text-generation-webui(可选)
如果您需要更丰富的功能(如模型切换、参数微调、聊天历史管理等),可以安装更强大的Web界面——text-generation-webui。
1 2 3 4 5 6 7
# 克隆text-generation-webui仓库cd ~/local_aigit clone https://github.com/oobabooga/text-generation-webuicd text-generation-webui# 安装Python依赖pip install -r requirements.txt
这个过程可能比较漫长,耐心等待依赖安装完成。
创建优化后的启动脚本:
1
nano ~/local_ai/start_webui.sh1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
#!/bin/bashcd ~/local_ai/text-generation-webui# 手机优化启动参数python server.py \--listen \--api \--model-dir ~/models \--model qwen2.5-1.5b-instruct-q4_k_m.gguf \--loader llama.cpp \--threads 4 \--n-gpu-layers 0 \--n-context 1024 \--cpu \--listen-port 7860 \--verbose
1 2 3 4 5
# 赋予执行权限chmod +x ~/local_ai/start_webui.sh# 启动Web UI./start_webui.sh
启动后,访问http://localhost:7860即可使用功能更丰富的Web界面。text-generation-webui提供了更多的定制选项,包括调整采样参数、保存聊天历史、加载不同模型等功能。
第六章:模型库——获取更多本地模型
不同的模型有不同的特点和适用场景。了解如何获取和使用各种模型,可以让您根据需求选择最合适的工具。
6.1 主要模型资源平台
Hugging Face(https://huggingface.co)是当前最大的开源模型托管平台,提供了海量的预训练模型和数据集。在Hugging Face上搜索GGUF标签可以筛选出可以直接用于Llama.cpp的模型文件。模型的模型卡(Model Card)页面通常包含模型的能力介绍、适用场景和使用建议。
ModelScope魔搭社区(https://modelscope.cn)是国内版的Hugging Face,提供了镜像服务,下载速度通常更快。特别适合网络条件不理想或需要下载大型模型的用户。
TheBloke的模型集合非常值得关注。这位开发者专门将各种流行模型转换为GGUF格式并提供多种量化版本。他的模型通常质量可靠,命名清晰,是新手入门的良好选择。
6.2 中文模型推荐
对于主要使用中文的用户,以下几个模型值得尝试:
Qwen2.5系列是阿里巴巴开发的开源大语言模型,在中文理解方面表现出色。Qwen2.5-1.5B适合手机端轻量使用,Qwen2.5-3B则在保持较好中文能力的同时提供了更强的推理能力。
Yi-1.5系列由零一万物开发,提供了1.5B到6B多个规模的模型。这些模型在中英文混合场景下表现均衡,适合需要处理双语内容的用户。
Chinese-LLaMA系列是专门针对中文进行优化的LLaMA变体,在中文指令遵循方面有针对性改进。Chinese-LLaMA-2-7B提供了较大的模型容量,但需要较多的内存资源。
6.3 专业领域模型
根据不同的使用需求,您可能需要专门优化的模型:
代码生成方面,CodeLlama系列是专门为编程任务优化的模型,支持多种编程语言,能够理解代码结构并提供编程建议。CodeLlama-7B-Instruct适合在手机上运行,提供代码补全和解释功能。
数学推理方面,Mathstral等专门针对数学问题优化的模型在处理计算和逻辑推理任务时表现更佳。如果您经常需要处理数学问题或数据计算,这类模型会更有帮助。
创意写作方面,MythoMax等模型在故事生成和角色扮演方面表现出色,生成的内容更具创意性和连贯性,适合内容创作场景。
6.4 批量下载脚本
为了方便管理多个模型,我们创建一个批量下载脚本:
1
nano ~/local_ai/download_models.sh1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
#!/bin/bash# 模型批量下载脚本MODEL_DIR="$HOME/models"echo"📥 开始下载模型..."echo"模型保存目录: $MODEL_DIR"echo""# 1. Qwen2.5-1.5B(中英双语,推荐入门)echo"【1/4】下载 Qwen2.5-1.5B..."if [ ! -f "$MODEL_DIR/qwen2.5-1.5b-instruct-q4_k_m.gguf" ]; thenwget -c https://mirrors.tuna.tsinghua.edu.cn/huggingface-models/Qwen/Qwen2.5-1.5B-Instruct-GGUF/qwen2.5-1.5b-instruct-q4_k_m.gguf -P $MODEL_DIRelseecho" 文件已存在,跳过下载"fi# 2. TinyLlama-1.1B(超轻量,速度快)echo"【2/4】下载 TinyLlama-1.1B..."if [ ! -f "$MODEL_DIR/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf" ]; thenwget -c https://mirrors.tuna.tsinghua.edu.cn/huggingface-models/TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf -P $MODEL_DIRelseecho" 文件已存在,跳过下载"fi# 3. Yi-1.5-6B(中文能力强,中高端首选)echo"【3/4】下载 Yi-1.5-6B..."if [ ! -f "$MODEL_DIR/yi-1.5-6b-q4_k_m.gguf" ]; thenwget -c https://mirrors.tuna.tsinghua.edu.cn/huggingface-models/georgesung/yi-1.5-6b-gguf/yi-1.5-6b-q4_k_m.gguf -P $MODEL_DIRelseecho" 文件已存在,跳过下载"fi# 4. CodeLlama-7B(编程专用)echo"【4/4】下载 CodeLlama-7B..."if [ ! -f "$MODEL_DIR/codellama-7b-instruct.q4_k_m.gguf" ]; thenwget -c https://mirrors.tuna.tsinghua.edu.cn/huggingface-models/TheBloke/CodeLlama-7B-Instruct-GGUF/codellama-7b-instruct.q4_k_m.gguf -P $MODEL_DIRelseecho" 文件已存在,跳过下载"fiecho""echo"✅ 模型下载完成!"echo"已下载的模型:"ls -lh $MODEL_DIR/*.gguf
1 2 3
# 运行批量下载chmod +x ~/local_ai/download_models.sh~/local_ai/download_models.sh
第七章:性能优化技巧
为了让本地AI在手机上运行得更加流畅,我们需要进行一系列的优化配置。这些优化可以显著提升响应速度,减少内存占用,并提高整体使用体验。
7.1 内存优化策略
内存是手机上最宝贵的资源之一。优化内存使用可以防止程序崩溃,并允许运行更大的模型。
监控内存使用情况是优化的第一步:
1 2 3 4 5 6 7 8
# 使用top命令查看进程和内存使用top -n 1# 或使用htop(如果已安装)htop# 查看内存和交换空间free -h
减少不必要的内存占用可以通过调整参数实现:
1 2 3 4 5 6 7 8
# 较小的上下文长度减少KV缓存占用./main -m model.gguf -c 512# 较小的批次大小./main -m model.gguf -b 64# 限制最大生成长度./main -m model.gguf -n 128
增加交换空间可以作为内存不足时的缓冲:
1 2 3 4 5 6 7 8
# 创建4GB交换文件(如果之前创建的不够大)ddif=/dev/zero of=$HOME/swapfile2 bs=1M count=4096chmod 600 $HOME/swapfile2mkswap $HOME/swapfile2swapon $HOME/swapfile2# 如果需要,删除旧的交换文件# rm $HOME/swapfile
7.2 推理速度优化
线程数调整需要找到最佳平衡点:
1 2 3 4 5 6
# 四核手机尝试不同线程数./main -m model.gguf -t 2 # 保守设置./main -m model.gguf -t 4 # 标准设置# 注意:并非线程越多越好# 过多的线程会增加上下文切换开销
预加载模型可以减少首次推理的等待时间:
1 2
# 创建预加载脚本nano ~/local_ai/preload_model.sh
1 2 3 4 5 6 7 8 9
#!/bin/bash# 预加载模型到内存/缓存MODEL_PATH="$HOME/models/qwen2.5-1.5b-instruct-q4_k_m.gguf"echo"🚀 预加载模型..."time cat"$MODEL_PATH" > /dev/nullecho"✅ 模型预加载完成!"echo"现在首次推理会更快。"
禁用不必要的功能可以减少开销:
1 2 3 4
./main -m model.gguf \--log-disable \ # 禁用日志输出--no-mmap \ # 禁用内存映射(更稳定但稍慢)--mlock \ # 锁定内存防止交换
7.3 批量处理优化
对于需要处理多个问题的场景,保持模型加载状态可以避免重复加载的开销:
1
nano ~/local_ai/batch_chat.py#!/usr/bin/env python3"""批量聊天脚本 - 保持模型加载状态,避免重复初始化开销"""import subprocessimport osimport sysclass BatchChat:def __init__(self, model_path, llama_dir):self.model = model_pathself.llama_dir = llama_dirself.process = Nonedef start(self):"""启动交互式模型进程"""cmd = [f'{os.path.expanduser("~")}/llama.cpp/main','-m', self.model,'-t', '4','-c', '1024','--interactive','--color','--prompt', '以下是与AI助手的对话。\n\n']print("🚀 启动模型进程...")self.process = subprocess.Popen(cmd,stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE,text=True,bufsize=1 # 行缓冲)# 等待初始化完成import timetime.sleep(3)print("✅ 模型已就绪!")def ask(self, question):"""发送问题并获取回答"""if not self.process:raise Exception("模型进程未启动")# 发送问题full_prompt = f"用户:{question}\n助手:"self.process.stdin.write(full_prompt + "\n")self.process.stdin.flush()# 读取回答import timetime.sleep(2) # 等待生成output = []for i in range(50): # 最多读取50行line = self.process.stdout.readline()if not line:
第八章:手机专属优化——散热与续航
长时间运行AI模型会导致手机发热和电量快速消耗。本章介绍一些手机专属的优化策略,帮助您更好地管理设备的温度和续航。
8.1 温度监控与控制
实时温度监控帮助您了解设备状态:
1 2 3 4 5
#安装Termux:API(需要从F-Droid单独安装)pkginstalltermux-api#查看电池和温度状态termux-battery-status
创建温度监控脚本:
1
nano~/local_ai/monitor_temp.sh1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
#!/bin/bash#温度监控脚本-当温度过高时自动采取措施whiletrue;do#获取电池温度temp=$(termux-battery-status|greptemperature|cut-d:-f2|tr-d',')if[-z"$temp"];then#如果termux-api不可用,尝试其他方法temp="未知"fiecho"📊$(date'+%H:%M:%S')|电池温度:${temp}°C"#温度判断和告警if["$temp"-gt45]2>/dev/null;thenecho"⚠️警告:温度过高(${temp}°C)"echo"建议:暂停推理任务,让设备冷却"#可选:降低CPU频率(需要root)#echo"powersave">/sys/devices/system/cpu/cpu0/cpufreq/scaling_governorfiif["$temp"-gt50]2>/dev/null;thenecho"🚨危险:温度严重过高(${temp}°C)"echo"建议:立即停止推理任务!"fi#每30秒检查一次sleep30done
8.2 省电模式配置
在不需要最大性能时,可以启用省电模式以延长电池续航:
1
nano~/local_ai/power_save.sh1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#!/bin/bash#省电模式配置脚本echo"🔋启用省电模式..."#降低CPU频率(需要root权限或特定设备支持)#echo"powersave">/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor#减少内存压力echo"10">/proc/sys/vm/swappiness#降低Termux进程优先级(减少CPU占用)if[!-z$$];thenrenice19$$2>/dev/null||echo"注意:无法调整进程优先级(需要root)"fiecho"✅省电模式已启用"echo"提示:使用完后可以运行power_normal.sh恢复正常模式"
1 2
#创建对应的普通模式脚本nano~/local_ai/power_normal.sh
1 2 3 4 5 6 7 8 9 10 11 12
#!/bin/bash#恢复正常模式echo"⚡切换到高性能模式..."#恢复CPU性能(需要root)#echo"performance">/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor#恢复正常内存策略echo"60">/proc/sys/vm/swappinessecho"✅已切换到高性能模式"
8.3 锁屏保活配置
防止Android系统后台清理Termux进程:
方法一:使用Termux的唤醒锁
1 2
#在脚本开头添加termux-wake-lock
方法二:关闭电池优化
进入手机「设置」→「应用」 找到并点击「Termux」 点击「电池」 选择「不优化」或「允许后台活动」
方法三:开机自启动服务
1 2 3 4
#创建启动脚本mkdir-p~/.termux/bootnano~/.termux/boot/ai_service.sh
1 2 3 4 5 6 7 8 9 10 11 12 13
#!/data/data/com.termux/files/usr/bin/bash#Termux开机自启动脚本#保持唤醒状态termux-wake-lock#进入工作目录cd~/local_ai#启动AI服务(可选:自动启动Web服务器)#./start_webui.shecho"🤖AI服务已就绪">>~/.termux/boot.log
8.4 物理散热方案
对于需要长时间运行模型的场景,物理散热方案可能很有帮助:
被动散热方案包括:
取下手机保护壳,增加散热面积 将手机放在金属表面(如铝合金桌面)上 使用手机散热支架
主动散热方案包括:
半导体散热背夹(可通过移动电源供电) 风扇冷却手机壳 专门的移动设备冷却器

手机液冷散热系统示意图
第 九章:实战应用场景
掌握基础知识后,让我们探索一些实际的应用场景。这些示例将帮助您将本地AI集成到日常工作和生活中。
9.1 离线个人助手
创建一个能够管理任务、记录笔记的个人AI助手:
1
nano~/local_ai/personal_assistant.py#!/usr/bin/env python3"""离线个人AI助手功能:任务管理、笔记记录、智能问答"""import jsonimport osfrom datetime import datetimefrom pathlib import Pathclass PersonalAssistant:def __init__(self, model_path):self.model = model_pathself.memory_file = os.path.expanduser("~/.assistant_memory.json")self.load_memory()def load_memory(self):"""加载保存的记忆数据"""try:with open(self.memory_file, 'r', encoding='utf-8') as f:self.memory = json.load(f)except FileNotFoundError:self.memory = {"tasks": [],"notes": {},"preferences": {}}def save_memory(self):"""保存记忆数据"""with open(self.memory_file, 'w', encoding='utf-8') as f:json.dump(self.memory, f, ensure_ascii=False, indent=2)def add_task(self, task, deadline=None):"""添加任务"""task_entry = {"content": task,"created": datetime.now().isoformat(),"deadline": deadline,"done": False}self.memory["tasks"].append(task_entry)self.save_memory()print(f"✅ 已添加任务:{task}")def list_tasks(self):"""列出所有未完成任务"""print("\n📋 待办任务:")for i, task in enumerate(self.memory["tasks"], 1):if not task["done"]:status = "☐" if not task["done"] else "☑"deadline = f"(截止:{task['deadline']})" if task["deadline"] else ""print(f" {i}. {status}{task['content']}{deadline}")def complete_task(self, index):"""完成任务"""try:idx = int(index) - 1if 0 <= idx < len(self.memory["tasks"]):self.memory["tasks"][idx]["done"] = Trueself.save_memory()print(f"✅ 已完成:{self.memory['tasks'][idx]['content']}")else:print("❌ 无效的任务编号")except ValueError:print("❌ 请输入有效的数字")def add_note(self, keyword, content):"""添加笔记"""self.memory["notes"][keyword] = {"content": content,"created": datetime.now().isoformat()}self.save_memory()print(f"✅ 已保存笔记:{keyword}")def search_notes(self, query):"""搜索笔记"""print(f"\n🔍 搜索笔记:{query}")results = []for keyword, data in self.memory["notes"].items():if query.lower() in keyword.lower() or query.lower() in data["content"].lower():results.append((keyword, data))if results:for keyword, data in results:print(f"\n📝 {keyword}:")print(f" {data['content']}")else:print("未找到相关笔记")def call_local_model(self, prompt):"""调用本地模型"""import subprocesscmd = [os.path.expanduser("~/llama.cpp/main"),'-m', self.model,'-t', '4','-c', '1024','-n', '256','--temp', '0.7','-p', prompt]try:result = subprocess.run(cmd,capture_output=True,text=True,timeout=120)return result.stdout.strip()except subprocess.TimeoutExpired:return "⚠️ 模型响应超时,请重试"except Exception as e:return f"⚠️ 调用模型失败:{str(e)}"def chat(self, message):"""智能对话(结合记忆)"""context = f"""当前时间:{datetime.now().strftime('%Y-%m-%d %H:%M')}待办任务数:{sum(1for t in self.memory['tasks'] ifnot t['done'])}用户说:{message}请结合以上信息,用中文友好地回答用户的问题。"""response = self.call_local_model(context)return responsedef run_cli(self):"""运行命令行交互"""print("\n🤖 个人AI助手已启动")print("命令提示:")print(" task add <内容> - 添加任务")print(" task list - 列出任务")print(" task done <编号> - 完成任务")print(" note add <关键词> <内容> - 添加笔记")print(" note search <关键词> - 搜索笔记")print(" chat <消息> - AI对话")print(" exit - 退出")while True:try:cmd = input("\n🎯 请输入命令: ").strip()if cmd in ['exit', 'quit', '退出']:print("👋 再见!")breakif not cmd:continueparts = cmd.split(' ', 2)action = parts[0].lower()if action == 'task':if len(parts) < 2:print("❌ 请指定子命令(add/list/done)")elif parts[1] == 'add' and len(parts) == 3:self.add_task(parts[2])elif parts[1] == 'list':self.list_tasks()elif parts[1] == 'done' and len(parts) == 3:self.complete_task(parts[2])else:print("❌ 无效的任务命令")elif action == 'note':if len(parts) < 2:print("❌ 请指定子命令(add/search)")elif parts[1] == 'add' and len(parts) == 3:# note add 关键词 内容content_parts = parts[2].split(' ', 1)if len(content_parts) == 2:self.add_note(content_parts[0], content_parts[1])else:print("❌ 请输入笔记关键词和内容")elif parts[1] == 'search' and len(parts) == 3:self.search_notes(parts[2])else:print("❌ 无效的笔记命令")elif action == 'chat' and len(parts) == 2:print("\n🤖 思考中...")response = self.chat(parts[1])print(f"\n💬 {response}")else:print("❌ 未知命令,请输入 'help' 查看帮助")except KeyboardInterrupt:print("\n👋 再见!")breakexcept Exception as e:print(f"❌ 发生错误:{str(e)}")if __name__ == "__main__":model = os.path.expanduser("~/models/qwen2.5-1.5b-instruct-q4_k_m.gguf")if not os.path.exists(model):print(f"❌ 模型文件不存在:{model}")print("请先下载模型文件")else:assistant = PersonalAssistant(model)assistant.run_cli()
9.2 文档摘要助手
快速总结长文档的核心内容:
1
nano ~/local_ai/summarize.sh1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
#!/bin/bash# 文档摘要助手if [ $# -eq 0 ]; thenecho"用法:./summarize.sh <文档文件路径>"echo"支持格式:.txt, .md"exit 1fiDOCUMENT="$1"MODEL="$HOME/models/qwen2.5-1.5b-instruct-q4_k_m.gguf"if [ ! -f "$DOCUMENT" ]; thenecho"❌ 文件不存在:$DOCUMENT"exit 1fiecho"📄 正在读取文档..."content=$(head -c 3000 "$DOCUMENT")filename=$(basename"$DOCUMENT")echo"🤖 正在生成摘要..."prompt="请用中文总结以下文档的主要内容,格式要求:1. 用3-5个要点概括核心内容2. 每个要点一句话3. 最后用一句话总结文档的整体主题文档标题:$filename文档内容:$content..."~/llama.cpp/main -m "$MODEL" \-t 4 \-n 512 \--temp 0.5 \-p "$prompt"
9.3 代码审查助手
帮助审查和解释代码:
1
nano ~/local_ai/code_review.py#!/usr/bin/env python3"""代码审查助手"""import subprocessimport osimport sysdef review_code(filepath):"""审查代码并提供改进建议"""if not os.path.exists(filepath):print(f"❌ 文件不存在:{filepath}")return# 读取代码文件with open(filepath, 'r', encoding='utf-8') as f:code = f.read()# 根据文件类型选择合适的提示词file_ext = os.path.splitext(filepath)[1].lower()if file_ext == '.py':prompt = f"""请审查以下Python代码,从以下方面提供详细反馈:1. 潜在bug和安全风险2. 性能优化建议3. 代码风格问题(PEP 8)4. 可改进的设计模式5. 是否有更好的实现方式请用中文回答,先列出问题,然后给出改进后的代码示例。代码:{code[:2000]}"""elif file_ext in ['.js', '.ts']:prompt = f"""请审查以下JavaScript/TypeScript代码,从以下方面提供反馈:1. 潜在bug2. 内存泄漏风险3. 异步处理问题4. 代码可读性5. ES6+最佳实践代码:{code[:2000]}"""else:prompt = f"""请审查以下代码,从以下方面提供反馈:1. 潜在问题2. 改进建议3. 代码质量评估代码:{code[:2000]}"""# 调用本地模型cmd = [os.path.expanduser("~/llama.cpp/main"),'-m', os.path.expanduser("~/models/codellama-7b-instruct.q4_k_m.gguf"),'-t', '4','-c', '1024','-n', '512','--temp', '0.3','-p', prompt]print(f"🔍 正在审查代码:{os.path.basename(filepath)}")print("-" * 50)try:result = subprocess.run(cmd,capture_output=True,text=True,timeout=180)if result.returncode == 0:print(result.stdout)else:print(f"❌ 审查失败:{result.stderr}")except subprocess.TimeoutExpired:print("⚠️ 审查超时,请尝试更小的代码片段")if __name__ == "__main__":if len(sys.argv) < 2:print("用法:python code_review.py <代码文件路径>")sys.exit(1)review_code(sys.argv[1])
第十章:故障排除指南
在使用本地AI的过程中,可能会遇到各种问题。本章汇总了常见问题及其解决方案,帮助您快速排除故障。
10.1 内存相关问题
问题表现:程序突然终止,终端显示「Killed」或「Process killed」。
诊断方法:
1 2 3 4 5
# 查看内存使用free -h# 查看系统日志中的内存相关信息dmesg | grep -i "killed\|memory\|oom"
解决方案:
使用更小的模型:如果当前使用的是7B模型,切换到1.5B或3B模型 增加交换空间:
1 2 3 4 5
# 创建更大的交换文件ddif=/dev/zero of=$HOME/swapfile_large bs=1M count=4096chmod 600 $HOME/swapfile_largemkswap $HOME/swapfile_largeswapon $HOME/swapfile_large
减少参数占用:
1 2 3 4 5
# 降低上下文长度./main -m model.gguf -c 512# 限制生成长度./main -m model.gguf -n 128
关闭其他应用:在运行AI之前,关闭不必要的后台应用释放内存
10.2 编译问题
问题表现:编译过程中出现错误,提示缺少头文件或链接失败。
常见错误及解决方案:
clang未安装:
1
pkg install clangCMake错误:
1 2 3 4 5 6 7
# 确保cmake已安装pkg install cmake# 尝试使用make直接编译cd llama.cppmake cleanmake -j2
内存不足导致编译中断:
1 2
# 减少并行编译任务make -j1
10.3 模型加载问题
问题表现:加载模型时出现错误,如「File not found」或格式错误。
诊断与解决:
文件路径错误:
1 2 3 4 5
# 确认文件存在ls -lh ~/models/# 使用绝对路径./main -m /data/data/com.termux/files/home/models/your_model.gguf
模型格式不兼容:确保使用GGUF格式的模型。如果下载了safetensors或其他格式的模型,需要转换。
下载不完整:
1 2 3 4 5 6
# 验证文件大小ls -lh ~/models/*.gguf# 重新下载损坏的文件rm ~/models/broken_model.ggufwget -c <download_url>
10.4 输出质量问题
问题表现:模型输出乱码、重复内容或不连贯的句子。
解决方案:
调整温度参数:
1 2
# 降低温度使输出更确定性./main -m model.gguf --temp 0.3
增加重复惩罚:
1
./main -m model.gguf --repeat_penalty 1.2 --no_repeat_ngram_size 3使用更好的采样策略:
1
./main -m model.gguf --mirostat 2 --mirostat-lr 0.1 --mirostat-ent 5.0检查输入提示词:确保提示词格式正确且清晰
10.5 性能问题
问题表现:生成速度过慢,每秒只有几个token。
诊断与优化:
检查CPU频率:
1 2 3 4
# 查看当前CPU频率cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq# 如果频率过低,可能是温度过高导致降频
优化线程数:
1 2 3
# 尝试不同的线程数./main -m model.gguf -t 2 # 更少的线程可能反而更快./main -m model.gguf -t 4 # 标准设置
使用更激进的量化:如果速度太慢,考虑使用Q3_K_L或Q2_K量化版本
关闭彩色输出:
1
./main -m model.gguf --no-color第十一章:性能对比测试
为了帮助您更好地了解不同配置下的性能表现,我们进行了系统的基准测试。以下数据基于实际测试得出,可以作为选择配置的参考。
11.1 测试环境
测试设备:OnePlus 12(16GB RAM,骁龙8 Gen 3)操作系统:Android 14 + TermuxLlama.cpp版本:最新编译版本
11.2 不同模型的性能对比
11.3 不同量化级别的对比
以Qwen2.5-1.5B为例:
| 推荐默认 | ||||
11.4 不同CPU配置的性能对比
测试模型:Qwen2.5-1.5B(Q4_K_M)
11.5 性能优化建议
基于测试结果,我们提出以下建议:
追求速度:选择TinyLlama或Qwen2.5-1.5B,使用Q4_K_M或更激进的量化,线程数设为4。
追求质量:选择Yi-1.5-6B或更大的模型,使用Q5_K_M或Q8_0量化,线程数设为4-6。
内存紧张:选择TinyLlama,使用Q3_K_M量化,上下文长度设为512。
平衡体验:Qwen2.5-1.5B是最佳平衡点,适合大多数用户日常使用。
第十二章:一键部署脚本
为了让整个部署过程更加便捷,我们编写了一个完整的一键部署脚本。运行此脚本将自动完成环境配置、Llama.cpp编译、模型下载和配置。
12.1 完整一键部署脚本
1
nano ~/local_ai/auto_deploy.sh```bash#!/bin/bash# ============================================================================# 安卓手机本地AI一键部署脚本# 适用于:Termux环境(Android 7.0+)# ============================================================================# 颜色输出RED='\033[0;31m'GREEN='\033[0;32m'YELLOW='\033[1;33m'BLUE='\033[0;34m'NC='\033[0m' # No Color# 配置变量TERMUX_DIR="$HOME"LOCAL_AI_DIR="$HOME/local_ai"MODELS_DIR="$HOME/models"LLAMA_DIR="$HOME/llama.cpp"SWAP_SIZE=2048 # 交换文件大小(MB)echo -e "${BLUE}╔═══════════════════════════════════════════════════════╗${NC}"echo -e "${BLUE}║ 🚀 安卓手机本地AI一键部署脚本 v1.0 ║${NC}"echo -e "${BLUE}╚═══════════════════════════════════════════════════════╝${NC}"echo ""# 检查Termux环境check_termux() {echo -e "${BLUE}📋 检查环境...${NC}"if [ ! -d "/data/data/com.termux" ]; thenecho -e "${RED}❌ 错误:请在Termux中运行此脚本${NC}"exit 1fiecho -e "${GREEN}✅ Termux环境检测通过${NC}"}# 更新软件包update_packages() {echo ""echo -e "${BLUE}[1/5] 更新软件包...${NC}"pkg update -ypkg upgrade -yecho -e "${GREEN}✅ 软件包更新完成${NC}"}# 安装依赖install_dependencies() {echo ""echo -e "${BLUE}[2/5] 安装编译工具链和依赖...${NC}"# 开发工具pkg install -y git clang cmake make ninja binutils python python-pippkg install -y wget curl# 科学计算库pkg install -y openblas libopenblas liblapack# 换用清华源(如果用户需要)# termux-change-repoecho -e "${GREEN}✅ 依赖安装完成${NC}"}# 配置交换空间setup_swap() {echo ""echo -e "${BLUE}[3/5] 配置虚拟内存(交换空间)...${NC}"SWAP_FILE="$HOME/swapfile"if [ -f "$SWAP_FILE" ]; thenecho -e "${YELLOW}⚠️ 交换文件已存在,跳过创建${NC}"elseecho "创建 ${SWAP_SIZE}MB 交换文件..."dd if=/dev/zero of="$SWAP_FILE" bs=1M count=$SWAP_SIZEchmod 600 "$SWAP_FILE"mkswap "$SWAP_FILE"swapon "$SWAP_FILE"# 添加到启动脚本if ! grep -q "swapon.*swapfile" ~/.bashrc 2>/dev/null; thenecho "swapon $HOME/swapfile" >> ~/.bashrcfiecho -e "${GREEN}✅ 交换空间配置完成${NC}"fi}# 编译Llama.cppbuild_llama() {echo ""echo -e "${BLUE}[4/5] 编译Llama.cpp...${NC}"if [ -f "$LLAMA_DIR/main" ]; thenecho -e "${YELLOW}⚠️ Llama.cpp已编译,跳过${NC}"elsecd $TERMUX_DIRif [ ! -d "llama.cpp" ]; thengit clone https://github.com/ggerganov/llama.cppficd llama.cppmake cleanmake -j4if [ -f "./main" ]; thenecho -e "${GREEN}✅ Llama.cpp编译成功${NC}"elseecho -e "${RED}❌ Llama.cpp编译失败${NC}"exit 1fifi}# 下载模型download_model() {echo ""echo -e "${BLUE}[5/5] 下载推荐模型...${NC}"mkdir -p "$MODELS_DIR"cd "$MODELS_DIR"MODEL_URL="https://mirrors.tuna.tsinghua.edu.cn/huggingface-models/Qwen/Qwen2.5-1.5B-Instruct-GGUF/qwen2.5-1.5b-instruct-q4_k_m.gguf"MODEL_NAME="qwen2.5-1.5b-instruct-q4_k_m.gguf"if [ -f "$MODEL_NAME" ]; thenfile_size=$(ls -lh "$MODEL_NAME" | awk '{print $5}')echo -e "${YELLOW}⚠️ 模型已存在(${file_size}),跳过下载${NC}"elseecho "正在下载 Qwen2.5-1.5B(Q4_K_M量化)..."wget -c "$MODEL_URL" -O "$MODEL_NAME"if [ $? -eq 0 ] && [ -f "$MODEL_NAME" ]; thenfile_size=$(ls -lh "$MODEL_NAME" | awk '{print $5}')echo -e "${GREEN}✅ 模型下载完成(${file_size})${NC}"elseecho -e "${RED}❌ 模型下载失败${NC}"fifi}# 创建快捷脚本create_shortcuts() {echo ""echo -e "${BLUE}📝 创建快捷启动脚本...${NC}"# 命令行聊天脚本cat > ~/start_ai_chat.sh << 'SCRIPT_EOF'#!/bin/bashcd ~/llama.cpp./main -m ~/models/qwen2.5-1.5b-instruct-q4_k_m.gguf \-t 4 -c 1024 -b 128 --color \--interactive-first \-r "用户:" \--prompt "以下是与AI助手的对话。助手乐于助人且富有创意。\n\n用户:你好\n助手:"SCRIPT_EOFchmod +x ~/start_ai_chat.sh# Web界面脚本cat > ~/start_web.sh << 'SCRIPT_EOF'#!/bin/bashcd ~/llama.cpp./server -m ~/models/qwen2.5-1.5b-instruct-q4_k_m.gguf \-t 4 -c 1024 --port 8080 --host 0.0.0.0SCRIPT_EOFchmod +x ~/start_web.sh# 增强版聊天脚本cat > ~/local_ai/chat.sh << 'SCRIPT_EOF'#!/data/data/com.termux/files/usr/bin/bashecho "======================================"echo " 🤖 本地AI聊天助手 v1.0"echo "======================================"MODEL_PATH="$HOME/models/qwen2.5-1.5b-instruct-q4_k_m.gguf"LLAMA_DIR="$HOME/llama.cpp"cd $LLAMA_DIRif [ ! -f "$MODEL_PATH" ]; thenecho "❌ 模型不存在!请运行 ~/local_ai/auto_deploy.sh"exit 1fiecho "✅ 模型加载中..."echo "💡 输入 'quit' 退出"while true; doread -p "👤 你: " user_inputif [ "$user_input" = "quit" ] || [ "$user_input" = "exit" ]; thenecho "👋 再见!"breakfiecho "🤖 AI: "./main -m "$MODEL_PATH" \-t 4 \-c 1024 \-b 128 \-n 256 \--temp 0.7 \--color \-p "用户说:$user_input\n助手回答:"echo ""doneSCRIPT_EOFchmod +x ~/local_ai/chat.shecho -e "${GREEN}✅ 快捷脚本创建完成${NC}"}# 显示使用说明show_usage() {echo ""echo -e "${GREEN}╔═══════════════════════════════════════════════════════╗${NC}"echo -e "${GREEN}║ 🎉 部署完成! ║${NC}"echo -e "${GREEN}╚═══════════════════════════════════════════════════════╝${NC}"echo ""echo -e "${YELLOW}📱 使用方法:${NC}"echo ""echo -e " ${GREEN}1. 命令行聊天:${NC}"echo " ~/start_ai_chat.sh"echo " 或 ~/local_ai/chat.sh"echo ""echo -e " ${GREEN}2. Web界面聊天:${NC}"echo " ~/start_web.sh"echo " 然后在手机浏览器访问:http://localhost:8080"echo ""echo -e " ${GREEN}3. 局域网访问(电脑浏览器):${NC}"echo " 先查看手机IP:ifconfig | grep inet"echo " 然后访问:http://<手机IP>:8080"echo ""echo -e "${YELLOW}📁 文件位置:${NC}"echo " 模型目录:~/models/"echo " 工作目录:~/local_ai/"echo " Llama.cpp:~/llama.cpp/"echo ""echo -e "${YELLOW}💡 下一步建议:${NC}"echo " - 尝试不同的模型(见第六章)"echo " - 优化性能设置(见第七章)"echo " - 开发自定义应用(见第九章)"echo ""}# 主流程main() {check_termuxupdate_packagesinstall_dependenciessetup_swapbuild_llamadownload_modelcreate_shortcutsshow_usage}# 运行主流程main```
12.2 使用一键部署脚本
1 2 3 4
# 运行一键部署脚本cd ~/local_aichmod +x auto_deploy.sh./auto_deploy.sh
脚本将自动执行以下步骤:
检查Termux环境 更新软件包 安装编译工具链和依赖 配置2GB交换空间 编译Llama.cpp 下载Qwen2.5-1.5B推荐模型 创建快捷启动脚本
整个过程可能需要30分钟到1小时,取决于您的网络速度和手机性能。完成后,您就可以立即开始使用本地AI了!
第十三章:高级技巧与扩展
掌握基础部署后,让我们探索一些高级技巧,让本地AI变得更加强大和灵活。
13.1 多模型切换
在同一台手机上运行多个模型,并轻松切换:
1
nano ~/local_ai/switch_model.sh1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
#!/bin/bash# 多模型切换脚本MODELS_DIR="$HOME/models"LLAMA_DIR="$HOME/llama.cpp"echo"📚 可用模型:"echo""# 列出所有模型i=1for model in"$MODELS_DIR"/*.gguf; doif [ -f "$model" ]; thenname=$(basename"$model")size=$(ls -lh "$model" | awk '{print $5}')echo" $i. $name ($size)"models[$i]="$model"((i++))fidoneif [ ${#models[@]} -eq 0 ]; thenecho" 未找到模型文件!"exit 1fiecho""read -p "请选择模型编号(1-$((i-1))):" choiceif [ -z "${models[$choice]}" ]; thenecho"❌ 无效选择"exit 1fiselected_model="${models[$choice]}"echo""echo"✅ 已选择:$(basename "$selected_model")"echo"💡 创建别名以快速切换..."# 创建快捷别名alias_cmd="alias ai-$(basename "$selected_model" | cut -d. -f1)='cd $LLAMA_DIR && ./main -m \"$selected_model\" -t 4 -c 1024 --color'"echo"$alias_cmd" >> ~/.bashrcecho""echo"✨ 现在可以使用以下命令启动模型:"echo" source ~/.bashrc"echo" ai-$(basename "$selected_model" | cut -d. -f1)"
13.2 API服务模式
将本地AI作为API服务,供其他应用程序调用:
1
nano ~/local_ai/api_server.py#!/usr/bin/env python3"""本地AI API服务器提供RESTful接口供其他应用调用"""from flask import Flask, request, jsonifyimport subprocessimport osimport threadingapp = Flask(__name__)# 模型配置MODEL_PATH = os.path.expanduser("~/models/qwen2.5-1.5b-instruct-q4_k_m.gguf")LLAMA_MAIN = os.path.expanduser("~/llama.cpp/main")# 简单的请求队列(防止并发冲突)request_lock = threading.Lock()@app.route('/api/chat', methods=['POST'])def chat():"""处理聊天请求"""data = request.jsonif not data or 'message' not in data:return jsonify({"error": "缺少'message'参数"}), 400user_message = data['message']max_tokens = data.get('max_tokens', 256)temperature = data.get('temperature', 0.7)with request_lock:try:# 构建提示词prompt = f"用户说:{user_message}\n助手回答:"# 调用模型cmd = [LLAMA_MAIN,'-m', MODEL_PATH,'-t', '4','-c', '1024','-n', str(max_tokens),'--temp', str(temperature),'-p', prompt]result = subprocess.run(cmd,capture_output=True,text=True,timeout=120)if result.returncode == 0:response = result.stdout.strip()return jsonify({"response": response,"status": "success"})else:return jsonify({"error": result.stderr,"status": "error"}), 500except subprocess.TimeoutExpired:return jsonify({"error": "请求超时","status": "timeout"}), 408except Exception as e:return jsonify({"error": str(e),"status": "error"}), 500@app.route('/api/models', methods=['GET'])def list_models():"""列出可用模型"""models_dir = os.path.expanduser("~/models")models = []for f in os.listdir(models_dir):if f.endswith('.gguf'):path = os.path.join(models_dir, f)size = os.path.getsize(path)models.append({"name": f,"size_mb": round(size / (1024*1024), 2)})return jsonify({"models": models,"current": os.path.basename(MODEL_PATH)})@app.route('/api/health', methods=['GET'])def health():"""健康检查"""return jsonify({"status": "ok"})if __name__ == '__main__':print("🚀 启动API服务器...")print("📡 访问地址:http://localhost:5000")# 安装Flask(如果需要)# pip install flaskapp.run(host='0.0.0.0', port=5000, debug=False)
启动API服务器后,您可以编写各种应用程序来调用本地AI,包括:
自动化脚本 自定义聊天机器人 与其他服务集成
13.3 知识库增强
构建一个本地知识库,让AI基于特定文档回答问题:
1 2 3 4 5
mkdir -p ~/local_ai/knowledge_base# 添加文档到知识库echo"公司规定:工作时间为9:00-18:00" > ~/local_ai/knowledge_base/rules.txtecho"紧急联系人:张经理 138xxxxxxxx" > ~/local_ai/knowledge_base/contacts.txt
1
nano ~/local_ai/rag_chat.sh1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
#!/bin/bash# 知识库增强聊天QUESTION="$1"KB_DIR="$HOME/local_ai/knowledge_base"MODEL="$HOME/models/qwen2.5-1.5b-instruct-q4_k_m.gguf"# 搜索相关文档CONTEXT=""for file in"$KB_DIR"/*.txt; doif [ -f "$file" ]; then# 简单关键词匹配if grep -qi "$QUESTION""$file" 2>/dev/null; thenfilename=$(basename"$file")content=$(cat"$file")CONTEXT="${CONTEXT}【${filename}】\n${content}\n\n"fifidone# 如果没有找到相关内容,使用空上下文if [ -z "$CONTEXT" ]; thenCONTEXT="(知识库中没有找到相关信息)\n"fi# 构建提示词PROMPT="基于以下知识库信息回答用户的问题。知识库内容:${CONTEXT}用户问题:${QUESTION}请根据知识库内容回答。如果知识库中没有相关信息,请说明这一点。回答:"# 调用模型~/llama.cpp/main -m "$MODEL" \-t 4 \-c 1024 \-n 512 \--temp 0.5 \-p "$PROMPT"
第十四章:未来展望
本地AI正在快速发展,未来将有更多可能性。
14.1 硬件加速趋势
NPU普及是手机AI发展的重要方向。新一代旗舰手机开始配备专门的神经网络处理单元(NPU),能够高效执行AI推理。Llama.cpp社区正在开发NPU支持,未来版本可能实现显著的加速效果。
硬件厂商动态方面,苹果的Neural Engine、高通的AI Engine以及联发科的APU都在持续改进。虽然目前Llama.cpp对这些专有硬件的支持有限,但随着技术成熟,我们有望看到更好的兼容性。
14.2 模型发展趋势
端侧大模型是各大厂商正在推进的方向。高通、联发科等公司正在开发专门针对移动设备优化的模型架构,预计在未来1-2年内将出现更多可在手机上流畅运行的7B+参数模型。
模型蒸馏技术使得大模型的知识可以迁移到更小的模型中。这意味着未来的1B-3B模型可能具备接近现在7B模型的能力,进一步降低手机运行AI的门槛。
14.3 软件生态展望
标准化接口将使得本地AI更容易集成到各种应用中。类似Ollama的项目正在为本地AI提供统一的API接口,未来开发AI应用将更加便捷。
混合AI架构是另一个值得关注的趋势。在这种方式下,轻量级任务由本地AI处理,复杂任务则可以智能地路由到云端,实现性能和成本的平衡。
14.4 学习建议
如果您想进一步深入本地AI领域,建议关注以下方向:
模型微调:学习如何在自己的数据上微调模型,创建专属的AI助手。多模态扩展:探索支持图像、语音输入的本地AI方案。性能优化:深入了解量化技术、推理优化,进一步提升模型效率。应用开发:将本地AI集成到自己的应用中,创造独特的价值。
第十五章:社区与支持
在学习和使用本地AI的过程中,社区资源是非常宝贵的。
15.1 官方资源
Llama.cpp GitHub(https://github.com/ggerganov/llama.cpp)是官方项目所在地,包含了最新的代码、文档和问题追踪。您可以在这里报告bug、请求新功能或查看开发进度。
Llama.cpp Discord服务器是一个活跃的社区,开发者和其他用户经常在这里讨论技术问题和分享经验。
15.2 中文社区
知乎本地AI话题有许多中文用户分享的教程和经验。B站技术UP主经常发布关于本地AI部署的视频教程。GitHub中文项目如OpenMBPP等提供了适合中文用户的资源。
15.3 获取帮助
当遇到问题时,您可以:
查阅本文档的故障排除章节 搜索GitHub Issues中是否有类似问题 在社区论坛发帖求助(描述清楚问题现象和环境配置) 查看模型卡片(Model Card)了解特定模型的使用要求
15.4 资源链接汇总
总结
通过这篇教程,您已经掌握了在安卓手机上部署本地AI模型的完整流程。让我们回顾一下核心要点:
关键技能回顾
环境搭建方面,您学会了安装和配置Termux、编译Llama.cpp,以及管理模型文件。这些是整个部署过程的基础。
模型选择方面,您了解了不同配置的手机应该如何选择合适的模型,以及量化技术的原理和选择方法。
性能优化方面,您掌握了内存优化、推理加速、温度管理等技巧,能够让本地AI运行得更加流畅。
应用开发方面,您了解了如何创建实用的AI应用,从个人助手到文档摘要,再到代码审查。
核心价值总结
本地AI部署为您带来的核心价值包括:
隐私安全:所有数据都在本地处理,不会泄露给任何第三方。随时可用:不受网络条件限制,在任何环境下都能使用AI。成本可控:一次性投入,长期免费使用。高度可定制:可以根据需求自由调整和扩展。
下一步行动
建议您按照以下步骤开始您的本地AI之旅:
立即尝试:运行一键部署脚本,体验本地AI的基本功能。 探索模型:尝试不同的模型,找到最适合您需求的版本。 优化配置:根据您的使用习惯,调整参数获得最佳体验。 开发应用:将本地AI集成到您的工作流程中。
最后
手机本地AI代表了个人计算的一个重要趋势——将AI能力从云端带到用户手中。这不仅是技术上的进步,更是对数字主权和隐私保护理念的践行。希望这篇教程能够帮助您开启本地AI的探索之旅。
祝您使用愉快!如果有任何问题,欢迎在评论区交流讨论。
最后更新:2025年1月
版本:v1.0
本文档中的代码和说明已经过实际测试,但因Android系统和Termux版本更新,部分步骤可能需要根据实际情况调整。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 推荐软件|小红书助手:快速采集小红书平台数据,支持批量导出笔记、收藏夹、博主笔记、关键词笔记等内容
- 【半导体专场职位推荐-50】半导体软件研发工程师/半导体工艺测试技术专家/半导体照明研发工程师/半导体工艺技术工程师等岗位热招中~
- 鸿蒙智行,以创新引领突破,以协同加速向前鸿蒙智行汽车技术生态联盟,五界协同聚力.在一起,加速向前,共创未来出行新篇.
- iPhone壁纸|ios氛围感壁纸24张
- 鸿蒙智行,五界同感,敢为人先 在合作中探寻创新之路,敢于在技术上持续深耕.智行携五界 交出更高质量的出行答案.
- 【鸿蒙 · 每周PLOG】2026.01.01-01.09
- ios壁纸‖贴纸极繁风
- 华为鸿蒙智行首款豪华轿跑,尚界Z7曝光,售价或25万起,剑指小米SU7
- iOS伪装上架影视神器全揭秘苹果用户收藏备用
- 鸿蒙智行首款轿跑尚界Z7亮相!25万起搭载华为高阶智驾,Model 3遇强敌
