在备受瞩目的鸿蒙仓颉挑战赛中,一支由陈恒宇、李华南、陈天路组成的技术团队凭借自主研发的CangjieSmartQuery(仓颉智询)智能问答系统成功斩获殊荣。这款基于仓颉编程语言打造、依托RAG(检索增强生成)架构的智能问答系统,不仅展现了仓颉语言在AI领域的落地潜力,更以轻量化、本地化、高适配的特性,为智能问答场景提供了全新的解决方案。
CangjieSmartQuery团队的三位核心成员分工明确、协同高效,陈恒宇作为核心架构师,主导了整个项目的技术架构设计,负责仓颉语言核心模块的编写与逻辑搭建,从全局层面保障系统的稳定性与扩展性;李华南聚焦产品与功能规划,深度梳理用户需求与场景落地路径,同时参与关键功能的代码实现,让技术方案精准贴合实际应用场景;陈天路则深耕工程落地环节,主攻向量数据库API的开发与适配,完成ChromaDB与FastAPI的整合,为系统搭建起高效的数据检索底座。三人互补的技术背景与默契的协作模式,成为项目从构思到落地的核心支撑。
谈及开发初衷,团队表示,日常工作与学习中“海量文档找答案难”的痛点始终存在,传统关键词检索效率低下,而现有大模型问答又易脱离本地知识体系,且市面上的智能问答系统多基于Python等语言开发,缺乏对鸿蒙生态与仓颉语言的适配。基于此,团队希望依托仓颉编程语言,打造一款能够基于用户自有资料快速输出精准答案的轻量化智能问答系统,同时验证仓颉语言在AI场景下的落地可行性。
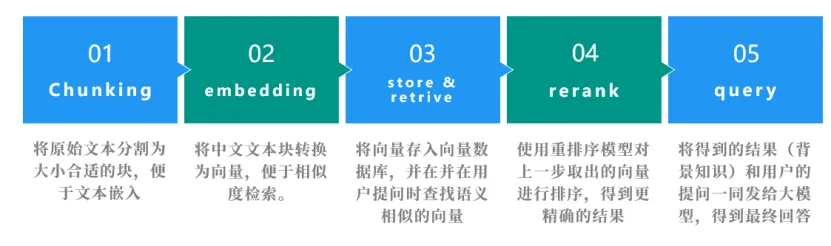
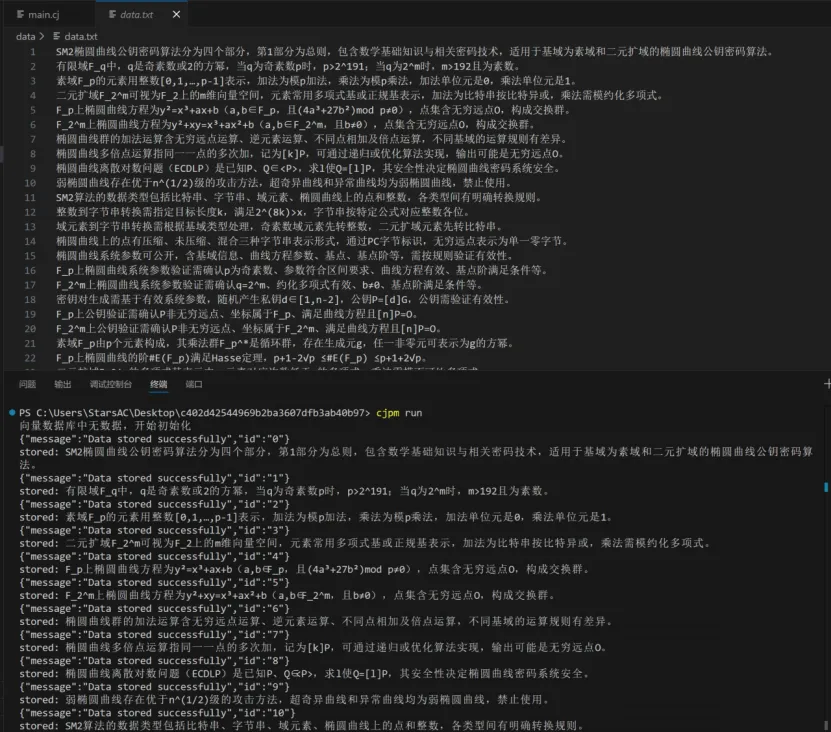
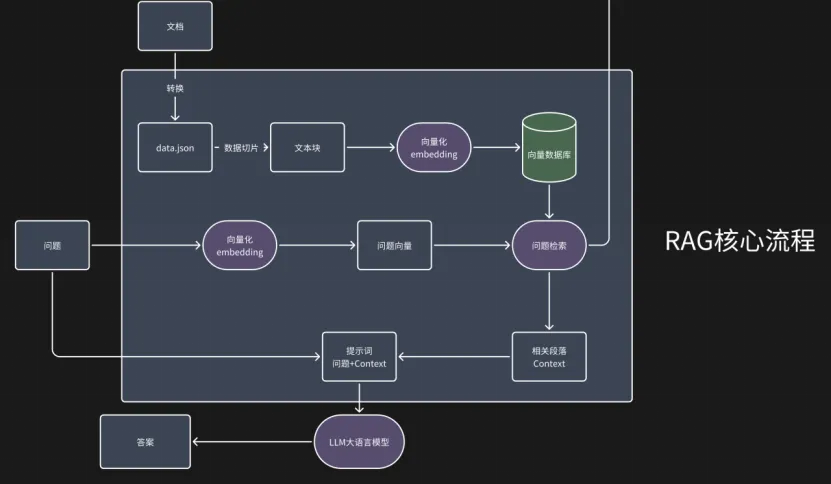
CangjieSmartQuery具备本地化向量数据库管理、精准检索与重排序、智能问答与对话记忆、流式输出等核心功能,用户仅需完成简单的环境配置与数据准备,即可通过便捷的操作实现智能问答。系统运行需依托仓颉编程语言环境、Python3.13+及相关依赖包,同时需对接SiliconFlow平台的AI服务,向量数据库则通过本地FastAPI服务部署。从技术架构来看,该系统采用经典的RAG架构,核心模块均由仓颉语言开发,仅向量数据库API层基于Python+FastAPI实现,整体涵盖数据处理、嵌入服务、向量数据库API、重排序服务、问答服务五大核心组件。其中,数据处理模块负责读取本地文本数据并生成向量写入数据库;嵌入服务对接SiliconFlow嵌入模型API完成文本向量化;重排序服务调用重排序模型优化检索结果;问答服务整合检索结果与对话上下文,调用大语言模型生成回答并支持对话记忆;向量数据库API则基于ChromaDB提供向量存储与检索的RESTful接口。
在具体工作流程上,用户提出问题后,系统首先判断是否为新对话,进而生成新的对话上下文或维持当前上下文,随后将问题文本嵌入为向量,在数据库中完成相似性检索,经重排序优化检索结果后构建提示词,最终调用大语言模型生成并返回回答,全流程形成高效闭环。值得一提的是,CangjieSmartQuery实现了多项技术突破,作为首个基于仓颉语言的RAG智能问答系统,它率先完成了RAG架构与仓颉语言的结合,验证了仓颉语言在AI应用开发中的可行性;针对跨语言服务协同难题,团队通过标准化RESTful接口设计,解决了仓颉编写的核心模块与Python实现的向量数据库API之间的数据交互、异常处理问题;在对话上下文管理方面,借助“新对话指令+上下文权重设计”,实现了对话记忆的灵活开关与精准维护,大幅提升多轮问答准确性。同时,系统支持全本地化部署,无需依赖复杂云服务,操作流程极简,有效降低了AI问答系统的使用门槛。
回顾备赛与开发过程,团队总结出诸多宝贵经验。其一,坚持“架构先行、语言适配”的思路,不盲目追求全仓颉开发,而是先确定RAG核心架构,再根据模块特性选择适配的开发语言,避免陷入“语言特性绑定”的陷阱;其二,采用“模块化测试+端到端验证”的方式,小步快跑推进开发,每完成一个模块先单独测试接口可用性,再逐步串联模块进行验证,及时发现并解决向量检索精度、重排序模型参数调优、对话上下文冲突等问题;其三,始终聚焦用户场景而非单纯堆砌技术,围绕“本地化、精准、易用”核心需求优化系统,让产品不仅能“跑起来”,更能真正“用起来”。
此次获奖不仅是对团队技术实力的肯定,更是仓颉语言在AI领域落地实践的重要突破。未来,团队将持续完善CangjieSmartQuery的代码实现并优化系统性能,计划新增OpenAI兼容的WebAPI接口,实现文档自动Chunking功能以支持整文档输入,同时探索与鸿蒙系统的深度适配,让智能问答能力融入鸿蒙应用与终端,进一步释放仓颉语言在鸿蒙生态中的价值。目前,CangjieSmartQuery的完整代码已开源,开发者可通过 https://gitcode.com/starsac/Cangjie-Examples/tree/XDUMsgBot 获取相关资源,共同探索仓颉语言在AI领域的更多可能。