近日,国内首个开源鸿蒙人形机器人训练场落户宁波慈溪,由乐聚智能牵头,斥资逾3000万元打造家电、商服等9大真实场景,旨在建立“算法—数据—技能”的闭环训练体系。这一动向释放了一个显著信号:数据采集正在告别“作坊模式”,成为支撑产业爆发的“新基建” 。
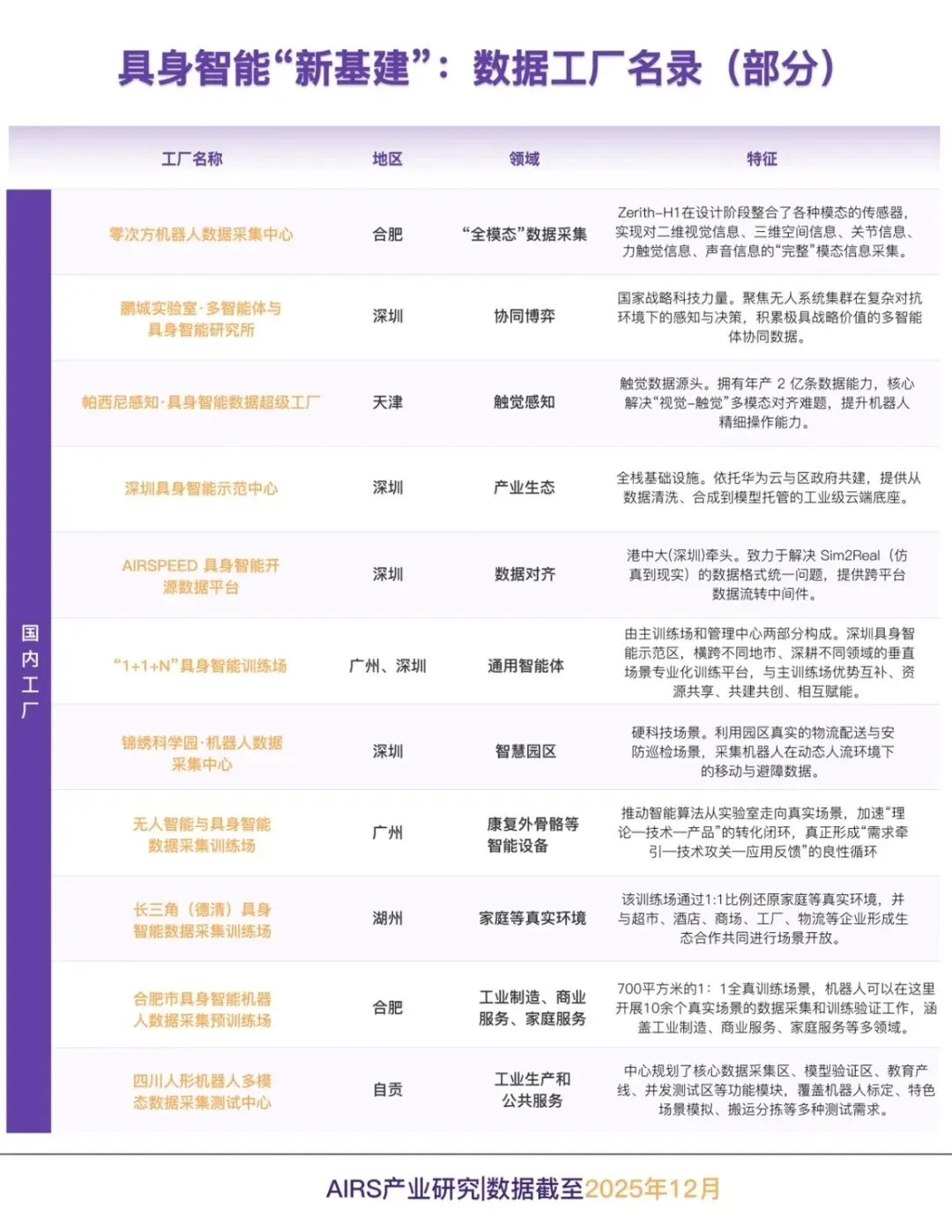
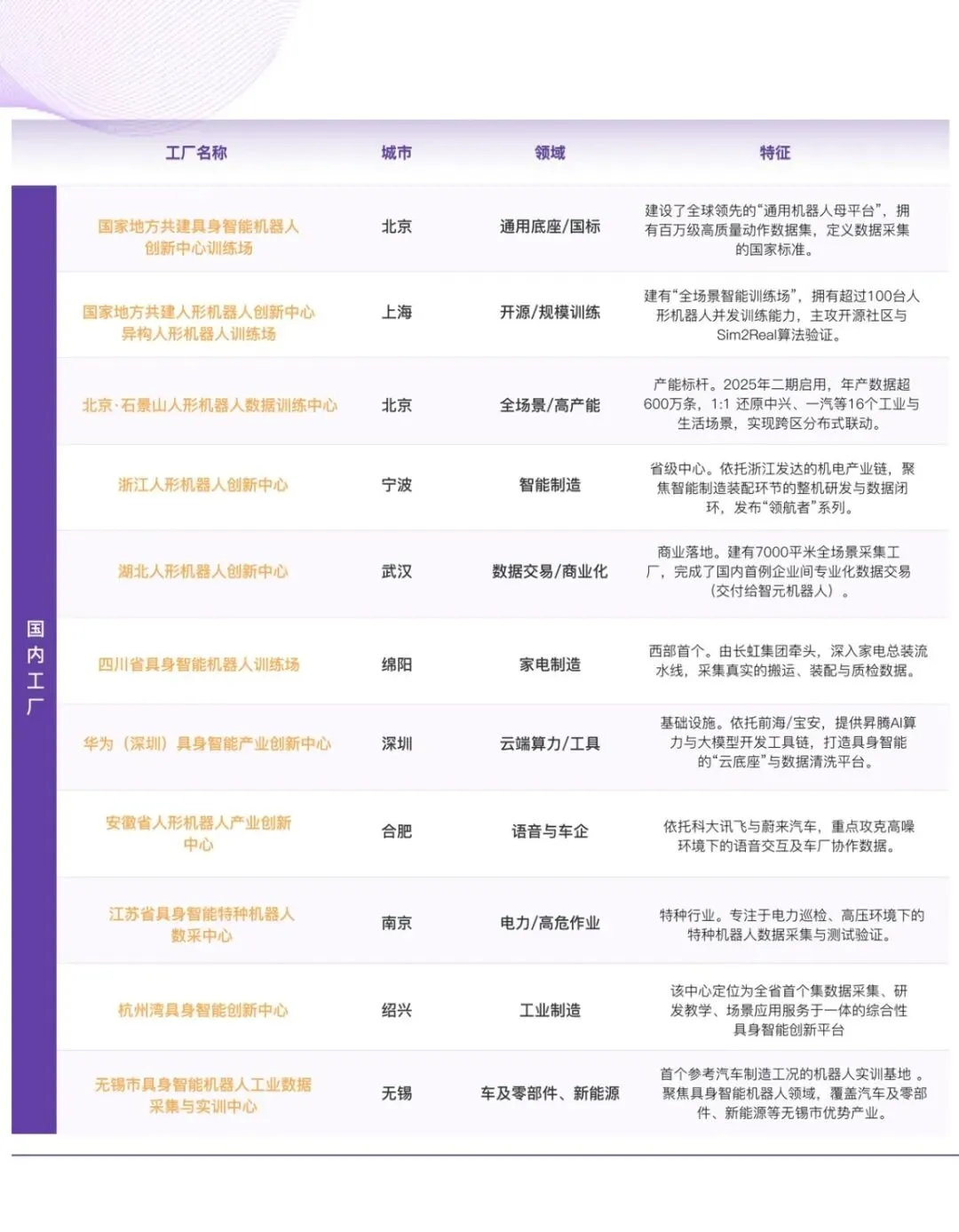
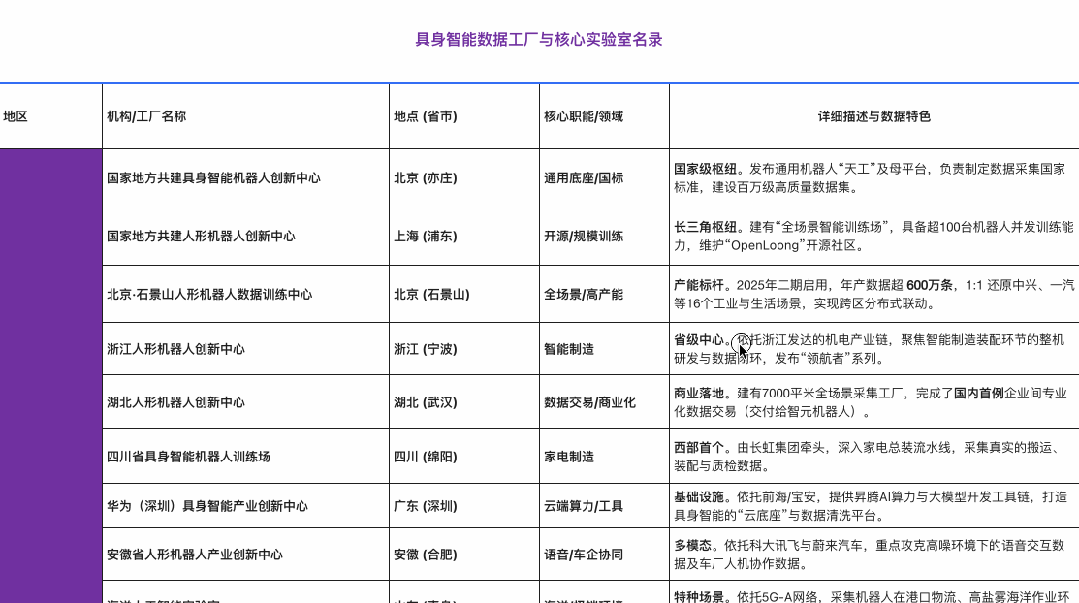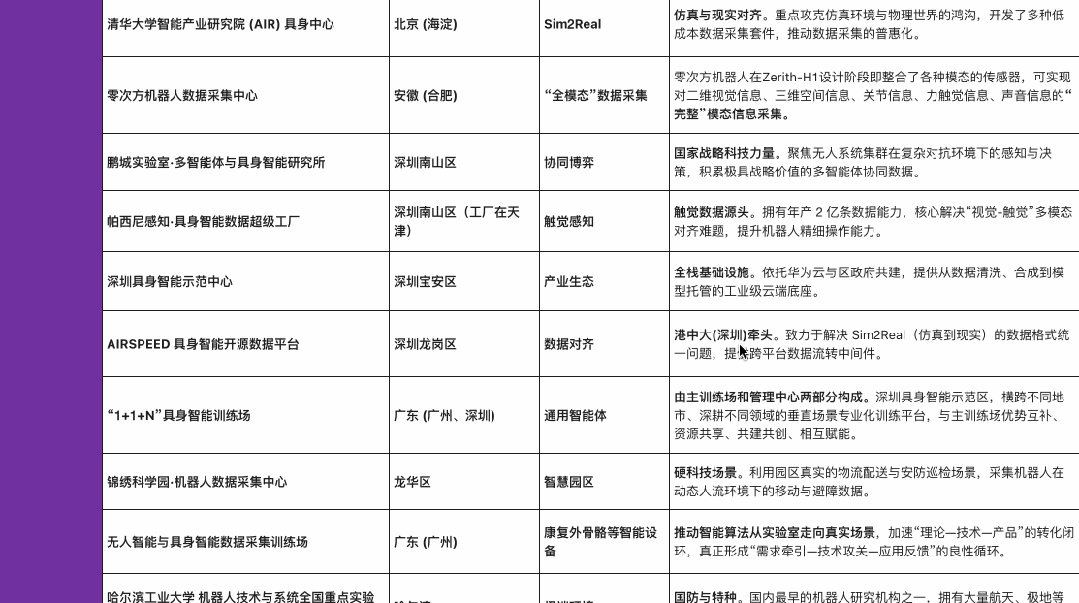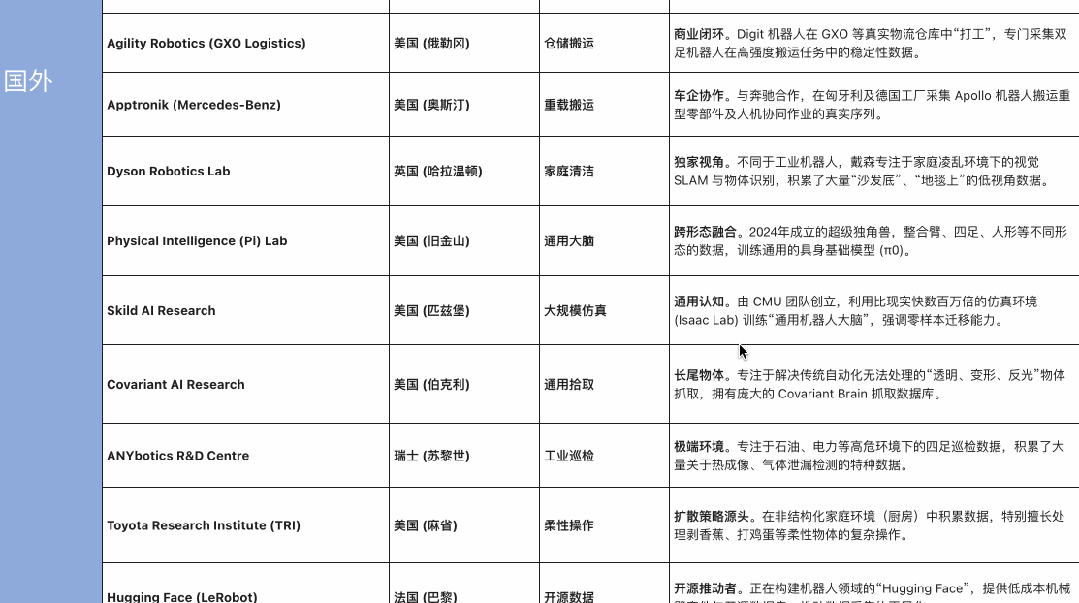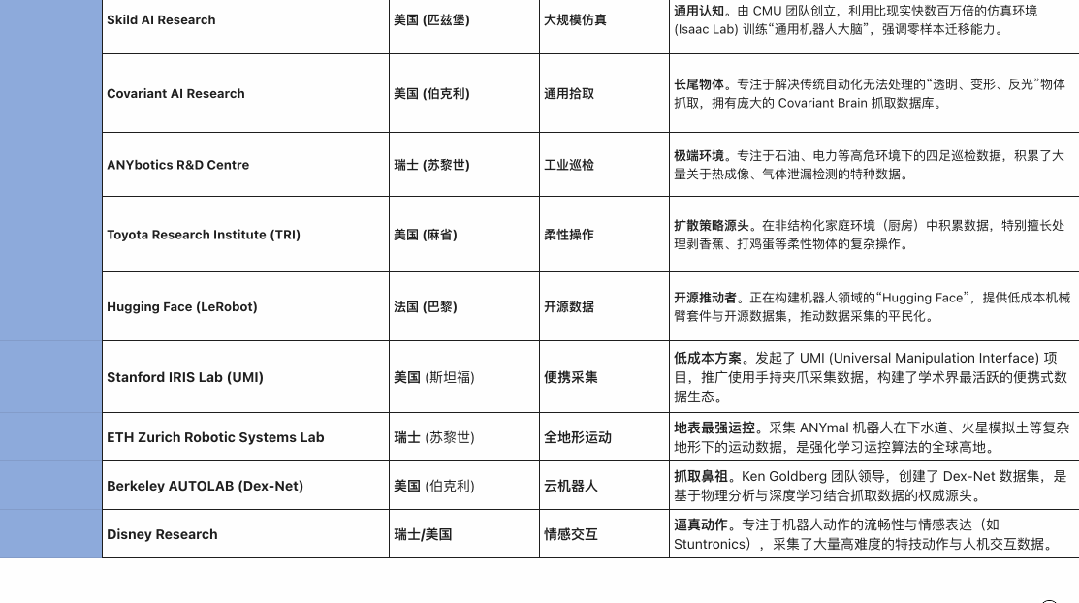
2025 下半年开始,具身智能领域的资本与订单正密集涌向产业链上游——数据工厂 。为了更直观地呈现这场全球范围内的变化,我们梳理了部分核心数据工厂名单。
截至 2025 年年底,数据库显示,中国已经有 50 个以上国家或省市区级人形机器人数据采集与训练中心处于使用或规划建设中,其中,50% 以上的数采中心已经在 2025 年正式投入使用。
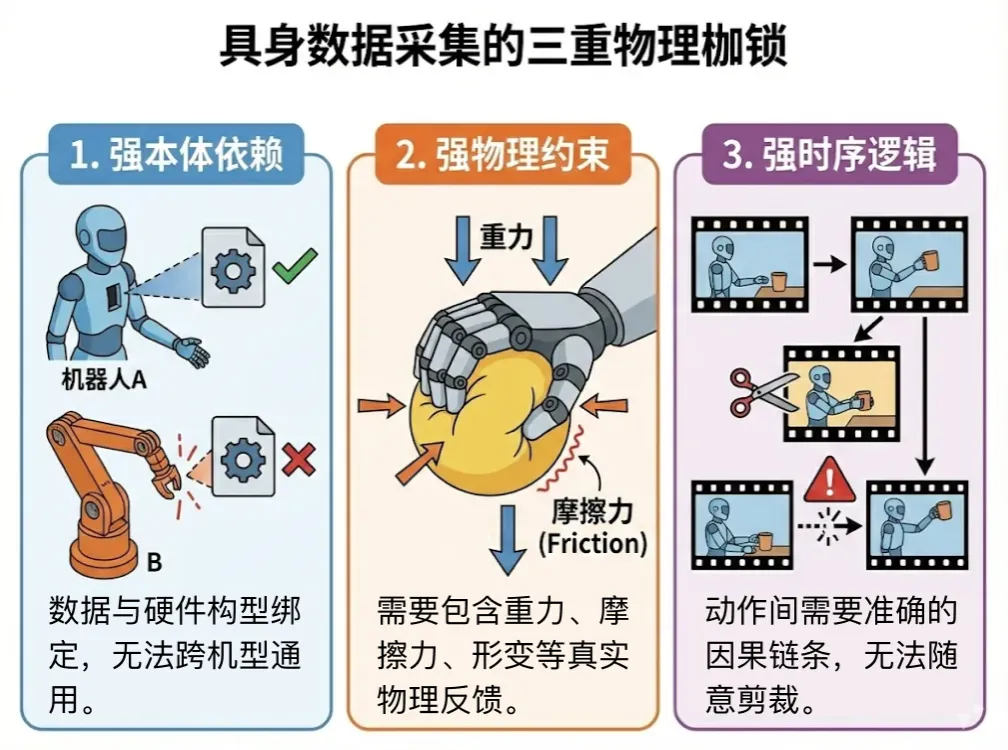
这一组数据标志着一个分水岭:数据采集开始走出实验室,演变为集中在大城市的“新基建”集群。随着硬件层面的规模化铺开,数据采集面临的难题也越发明显:不同于唾手可得的互联网文本,具身数据在采集上面临着三重“物理枷锁”。
强本体依赖: 数据需要与机器人构型(自由度、关节)高度绑定;
强物理约束: 需要包含摩擦力、重力、形变等真实物理反馈;
强时序逻辑: 动作之间存在因果链条,无法随意裁剪。
这使得高质量数据集的获取成本呈指数级上升。在这个阶段,谁能更高效地建设“数据工厂”,谁就掌握了通往 AGI 的入场券。
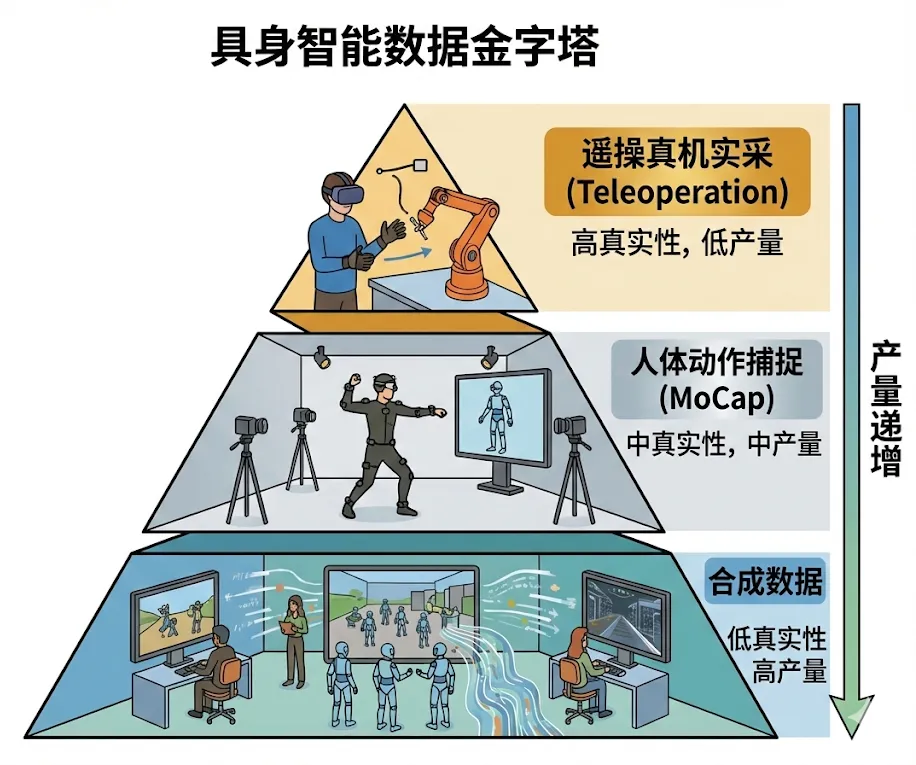
当下数据采集的主要范式,按照其产出的数据精度和数据量划分,大体符合“金字塔”型分布——高度代表数据的真实性,底面积代表数据的产量。
这是目前质量高、成本高的“黄金数据”。
采集方式: 采集员佩戴 VR 头显或外骨骼设备,通过动作映射,一比一地控制真实的机器人执行任务。
数据形态: 包含机器人关节角度、末端执行器位姿、视觉图像以及触觉反馈的State-Action Pairs。
核心优势: 还原度高,能完美解决与物品接触多的任务,如穿针引线、揉面团,完全没有仿真差距。
当数据采集从实验室走向“数据工厂”层面,面临的就不单纯是学术问题,而是复杂的工程化问题。
一个成熟的具身智能数据工厂,并非简单的“堆人堆设备”,它需要满足高并发、流程化与标准化的工业级要求:
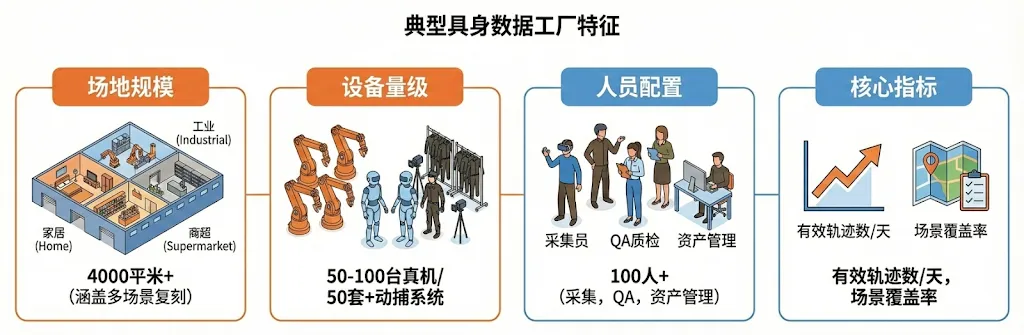
典型具身数据工厂特征
场地规模: 4000平米+(涵盖家居、工业、商超多场景复刻)
设备量级: 50-100台真机 / 50套+动捕系统
人员配置: 100人+(采集员、QA质检、资产管理)
核心指标: 有效轨迹数/天、场景覆盖率
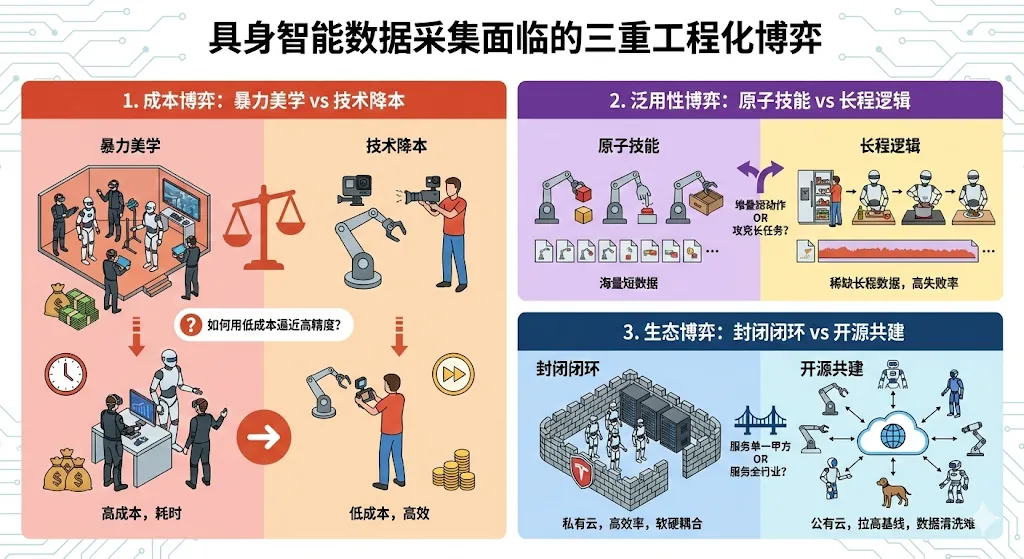
在路线清晰、代价显现后,数据工厂的建设面临着成本、效率与能力目标之间的三重工程化博弈:
成本博弈:高质高成本 vs 技术降本
数据工厂建设面临着“高精度”与“高规模”的艰难平衡。一方是以特斯拉为代表的重资产模式,用昂贵设备换取无损数据,但扩展成本极高;另一方是斯坦福 UMI 式的轻量化模式,试图用廉价终端换取爆发式增长。工程落地的胜负手,在于能否实现用算法补偿硬件——即通过更强的后处理能力,允许使用低成本采集设备,从而在有限预算下跑通大规模量产的商业模型。
泛用性博弈:原子技能 vs 长程逻辑
早期的工厂主要生产“原子技能”(如简单的抓取、放置)。但在工程落地中,机器人需要具备“做完一顿饭”的逻辑能力。这带来了博弈:是继续堆叠海量的短动作数据,还是投入数倍资源去攻克高失败率的“长程任务”? 前者容易刷数据量,后者才是智能的质变点。
生态博弈:封闭闭环 vs 开源共建
这是战略上的博弈。封闭模式(如特斯拉)能确保数据格式统一、软硬高度耦合,效率极高;而开源模式(如 Open X-Embodiment)虽然面临数据清洗难、标准不一的问题,但能通过生态力量快速拉高行业基线。对于数据工厂而言,是服务于单一甲方的“私有云”,还是做服务于全行业的“公有云”,决定了其商业模式的上限。
具身智能的竞争,比拼的是数据流转的效率,这不仅是一场技术冲刺,更是一场持久战。
真正的竞争壁垒,不在于数据集发布的那一刻,而在于谁拥有持续产生高质量、物理一致性数据的规模化生产能力。
关注公众号后回复“数据”
添加作者微信加入读者群交流👇