6 月 30 日,华为干了一件让 AI 圈没法装没看见的事——openPangu-2.0-Flash 正式开源上线了。
920 亿总参数,模型权重、推理代码、训推算子全放了出来。
半个月前在 HDC 2026 上,余承东说要把盘古开源。大家以为就是常规操作——放个权重,给个推理 demo。结果华为这次直接把底牌全摊了。
不是 920 亿负担,是 60 亿精兵
先纠正一个概念。openPangu-2.0-Flash 总参数量 920 亿(92B),但激活参数只有 60 亿(6B)。
怎么做到的?稀疏 MoE 架构。模型内部有大量"专家模块",每次任务只叫醒最相关的几个干活,大部分算力不参与计算。效果就是 920 亿的脑容量,跑起来只消耗 60 亿的体力。
同系列还有一个 Pro 版本,5050 亿总参、180 亿激活参,7 月上线。两块牌子一套班子,Flash 打轻量高效,Pro 打复杂任务。
两个版本统一支持 512K 上下文。长文档、代码库、多轮对话,上下文窗口够用。
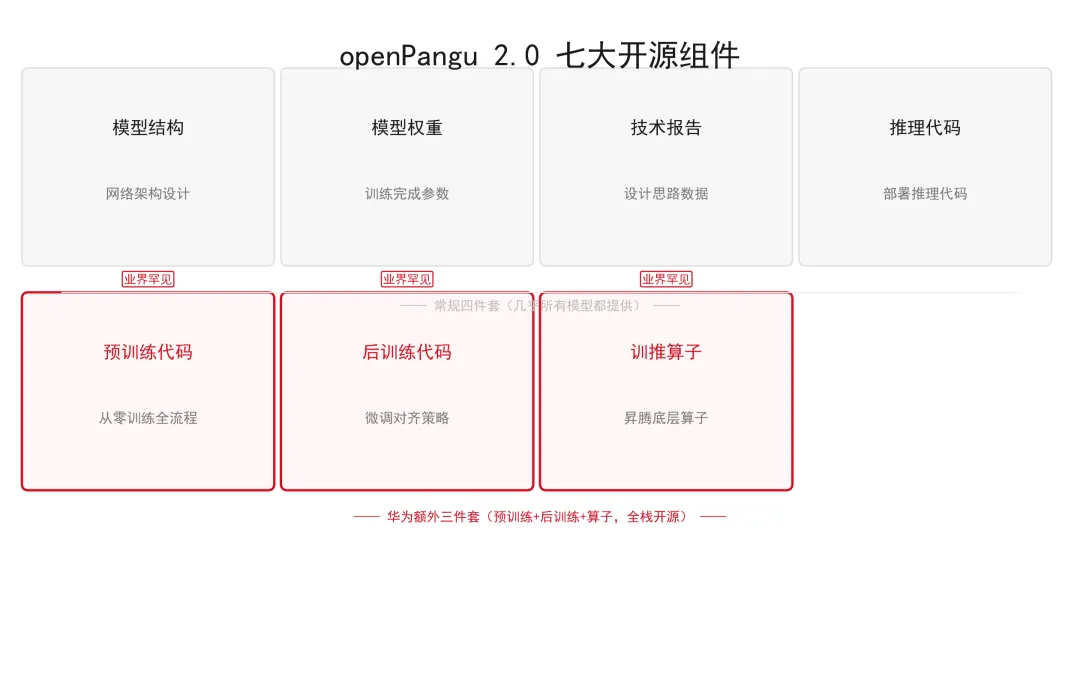
七张底牌,常规开源只给四张
这次开源最狠的不是参数规模,是开放程度。
业界主流开源大模型,标准配置是四样:模型结构、权重、技术报告、推理代码。拿到这四样可以直接用,没问题。
华为多了三样:预训练代码、后训练代码、训推算子。
区别在哪?权重和推理代码是"成品",拿来即用。预训练代码和后训练代码是"配方"和"工艺"——告诉你模型怎么炼出来的、微调用什么策略、数据怎么处理。训推算子则是让整个链条在昇腾芯片上高效运转的底层胶水层。
把这三样也交出来,等于从原材料到成品到产线,整个产线图都画出来了。不是为了秀肌肉,是要让开发者真正上手昇腾,降低使用国产算力的门槛。
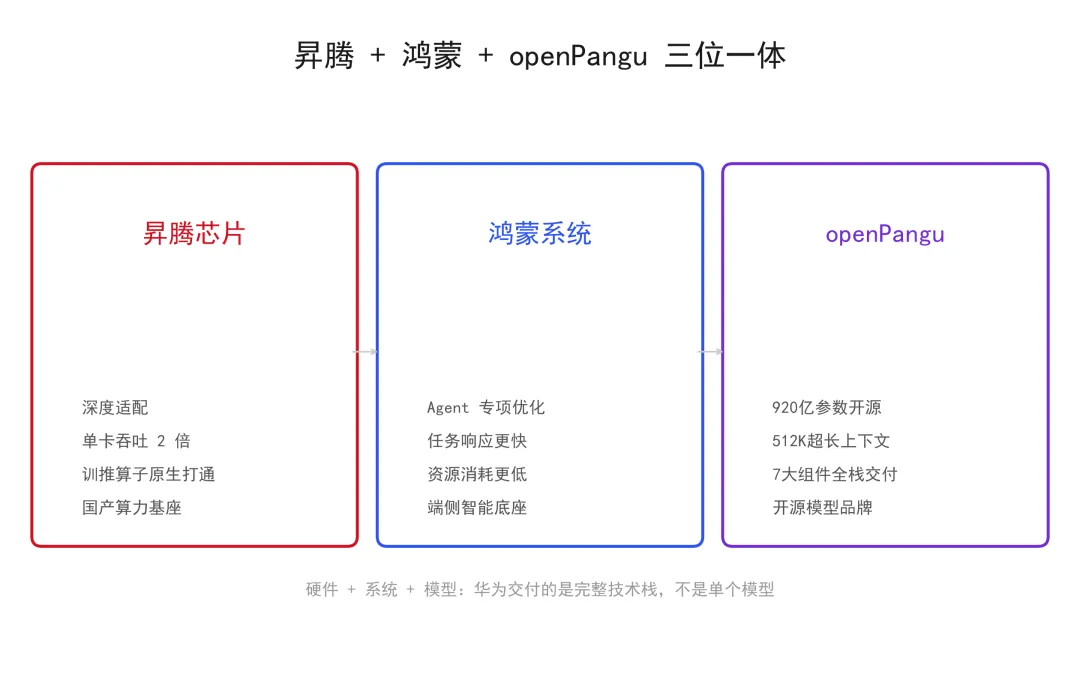
昇腾原生 + 鸿蒙原生,双重锁定
openPangu 不只是一个开源模型。
它的官方定位写得清楚:"通过昇腾原生训练与推理技术,为业界用好昇腾提供最佳实践参考,助力打造 Agent 时代强大的智能底座。"
翻译一下:华为不是来跟你比跑分的。它是来给昇腾生态搭样板间的。
深度适配昇腾芯片,单卡吞吐率达到行业主流开源模型的两倍。针对鸿蒙系统做了专项优化,Agent 任务的响应更快、执行更精准、资源消耗更低。
昇腾 + 鸿蒙 + openPangu,硬件、操作系统、模型——三合一。这才是华为真正想交付的东西。
余承东的军令状
HDC 2026 上余承东说了两句值得玩味的话。
第一句:"在我余承东的字典里,没有第二,只有第一。"
第二句比较坦诚:华为自留的算力有限,大部分昇腾算力优先供给国内其他企业。
这两句放在一起看,逻辑很清晰——华为在算力层面没有优势,但它选择了一条不同的路。不是堆算力,是开源生态。把模型、代码、算子全交出来,让整个产业一起用昇腾。昇腾用的人多了,生态就自然壮大了。
从 6 月 30 日起,七大组件分批上线。Flash 版先到,Pro 版 7 月跟上,其余组件下半年陆续交付。
GitCode 平台(gitcode.com/ascend-tribe)已上线。
出品方:AI 时代笔记